Real name:
First Name:
Andres
Last Name:
Frederic
Affiliation:
National Institute of Informatics
Job Title:
Associate Professor
In recent years, the fusion of artificial intelligence and semantic web technologies has paved the way for innovative approaches to managing and utilizing information. With the growing demand for structured gastronomical data, there is a need for well-defined ontologies that facilitate recipe organization, ingredient classification, nutritional insights, and personalized diet recommendations. The dataset presents a multilingual recipe ontology and knowledge graph, capturing critical relationships between ingredients, nutrition, cooking actions, and recipe planning.
 150 Views
150 Views
This dataset provides a comprehensive exploration of 1580 distinct Hindi dish categories, offering a cultural and culinary lens into India's rich gastronomic heritage. The classification encapsulates a diverse array of dishes spanning regional, seasonal, and festive cuisines, while highlighting the integral role of ingredients, cooking techniques, and cultural narratives.
75 Views
A 33K classification of dishes (in French) is an ambitious project aimed at categorizing the immense diversity of French gastronomy. France’s culinary heritage is deeply rooted in regional traditions, local ingredients, and refined techniques, making it one of the richest cuisines globally. Below is a high-level structure to approach such a detailed classification, breaking it down into broader categories, regional specialties, and ingredient-based subcategories.
37 Views
the dataset is related to an app-based framework for multivariate next-day price prediction using
GRU attention networks with rolling averages.
67 Views
These are the codes and models used in our experiments regarding our submitted article “Cheby-KANs:
Advanced Kolmogorov-Arnold Networks for Applying Geometric Deep Learning in Quantum Chemistry
Applications”. The code is developed using python programming language. In our paper we hae
developed the B-spline based KANs with a more powerful and much faster polynomials “shifted-
Chebyshev polynomials” of the first kind. Also, we integrated our new architecture with geometric deep
48 Views
This dataset comprises a comprehensive collection of PubMed abstracts and associated metadata focusing on the topic of multiple sclerosis (MS) in relation to social determinants and environmental factors, spanning publications from January 1, 2018, to November 15, 2024.
98 Views
The Universal Networking Language (UNL) UDE Dictionary for Indian Cooking is a pioneering framework aimed at facilitating seamless communication and knowledge sharing across diverse languages and cultures, with a special focus on the rich culinary traditions of India. This dictionary provides a comprehensive and structured representation of essential culinary terms, ingredients, cooking techniques, and descriptors in Hindi, paired with their corresponding UNL equivalents. Each entry includes a UNL term, a definition and examples.
44 Views
The Universal Networking Language (UNL) UDE Dictionary for French Cooking is a pioneering framework aimed at facilitating seamless communication and knowledge sharing across diverse languages and cultures, with a special focus on the rich culinary traditions of France. This dictionary provides a comprehensive and structured representation of essential culinary terms, ingredients, cooking techniques, and descriptors in French, paired with their corresponding UNL equivalents. Each entry includes a UNL term, a definition and examples.
28 Views
The Universal Networking Language (UNL) is a pioneering framework designed to facilitate seamless communication and knowledge sharing across different languages and cultures. This UNL French Dictionary focuses specifically on the rich and diverse world of French cuisine, offering a structured representation of culinary terms, ingredients, cooking techniques, and descriptors in French alongside their universal equivalents.
The UNL French Dictionary serves several key purposes:
32 Views
The Universal Networking Language (UNL) serves as a conceptual framework aimed at facilitating communication across different languages and cultures. In the context of culinary arts, the UNL dictionary provides a structured approach to represent Indian culinary terms, ingredients, cooking methods, and descriptors in a universally understandable manner.
39 Views
During our research in generating or optimizing molecules to be drug candidates by extending deep reinforcement learning and graph neural networks algorithms, we used GEOM data [1], and we had an idea to make a dataset obtained from molecules from GEOM to predit the activity towards COVID and the drug linkeness. We calculated over 200 descriptors for the molecules using RDKit [2]. We hope you enjoy using it.
References:
393 Views
The dataset aims to facilitate research in the optimization of the carbon footprint of recipes. Consisting of 30 Excel files processed through various Python scripts and Jupyter notebooks, the dataset serves as a versatile resource for both performance analysis and environmental impact assessment. The unique attribute of this dataset lies in its ability to calculate representative values of carbon footprint optimization through multiple algorithmic implementations.
262 Views
This Named Entities dataset is implemented by employing the widely used Large Language Model (LLM), BERT, on the CORD-19 biomedical literature corpus. By fine-tuning the pre-trained BERT on the CORD-NER dataset, the model gains the ability to comprehend the context and semantics of biomedical named entities. The refined model is then utilized on the CORD-19 to extract more contextually relevant and updated named entities. However, fine-tuning large datasets with LLMs poses a challenge. To counter this, two distinct sampling methodologies are utilized.
356 Views
In recent years, teaching-learning methods have emerged into a completely new dimension from what used to be a traditional approach. The in-person lectures have been converted into online virtual learning, the traditional record-keeping has been replaced by robust learning management systems which have made the teaching-learning process lot more efficient and convenient.
270 Views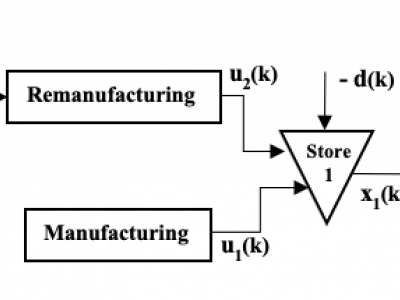
the focus of this dataset is to provid an open-loop solution for a stochastic problem with imperfect state information and
chance-constraints adjusted by an optimal gain.
95 Views
dataset for An open-loop solution for a stochastic problem with imperfect state information and chance-constraints adjusted by an optimal gain.
40 Views
The 5K EPP Dataset includes 5007 photos of water crystaks classified in 13 categories. This dataset was created under the leaderhip of Prof. Masaru Emoto.
333 Views