First Name
Sherin
Last Name
Moussa
Job Title
Professor

Children Arabic Utterances for Mispronunciation Detection Dataset
Audio samples were recorded from 27 Egyptian children (14 boys and 13 girls aged between 7 and 12 years old), where they pronounce 16 words. The files are organized into folders and subfolders that contain the following: the dataset is managed and separated into 2 folders (Correct / Wrong) pronunciations. The dataset is collected and annotated on segmental pronunciation errors by Arabic linguistics experts from NahdetMisr Publishing House (https://nahdetmisr.com/).
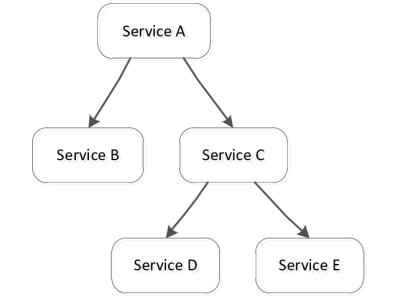
This file provides the main descriptive information about this services dependency graphs dataset to model web services compositions.
This dataset represents the services dependency graphs (SDGs) generated by our developed Mutual Information-based Services Dependency (MISD) model for 4 public services datasets.

This is the First Arabic voice Commands Dataset to provide personalized control of devices at smart homes for elder persons and persons with disabilities. The dataset contains 12 speakers, each saying 36 different phrases or words in Arabic language. The goal of this dataset is to use it in an Arabic smart home system to control home devices through voice. Participants were asked to say each phrase multiple times. The phrases to record were presented in a random order.
This is a protein negative interaction dataset, generated by our proposed method the “Features Dissimilarity-based Negative Generation” approach to generate protein negative sampling based on sequence data. It measures similarity of sequence characteristics without alignment based on Protein similarity. It achieved results of 97% compared to randomly generated negative dataset.

The dataset represents the negative interaction dataset of the Drugbank that has been generated from our proposed machine learning method based on drug similarity, which achieved an average accuracy of 95% compared to the randomly generated negative datasets in the literature. Drugbank was used as the drug target interaction dataset from https://go.drugbank.com/. It consists of 1,264 interactions among 504 drugs and 507 proteins. The dataset includes drugs names, their accession numbers, proteins names, their UniproteId on Uniprot at https://www.uniprot.org/.

The provided dataset is obtained by crawling through various websites to identify all the possible webpages that which can be used to determine to what degree they are exposed to attacks.
The global system for mobile communications (GSM) supports mobile operators for cellular networks. Huge devices are connected to obtain services through the internet. To avoid failures when connecting IoT devices to mobile networks, GSM has provided two datasets: IoT device connection efficiency and Mobile IoT (MIoT) common test cases (TCs) and guidelines as per the IoT systems specifications. GSM produces TCs at least each year since 2015 till present.

This dataset represents the main different unique learning behaviors that may be found in any group of learners in e-learning/educational systems. It represents 20 learners through 17 OERs.