Signal Processing

This dataset is utilized for the research of blind identification of CPM signal modulation order. The signal parameters in the dataset range as follows: modulation index from 0.125 to 1, modulation order of 2, 4, 8, pulse types including REC, RC, SRC, TFM, and GMSK, and correlation lengths of 1 to 8. The signals are oversampled by a factor of 10, transmitted through an additive white Gaussian noise (AWGN) channel, and the signal-to-noise ratio (SNR) ranges from 0 to 30dB.
- Categories:
 81 Views
81 Views
This dataset contains the measurement in an ultrawide band (UWB) system in the 6.5 GHz band, considering the presence of the human body as the only obstacle. There are measurements in line-of-sight condition to compare the results of the analysis performed. The measurements are part of our research on the adverse effects of the body shadowing in pedestrian localization systems. The measurements were obtained in three distinct scenarios.
- Categories:
801 Views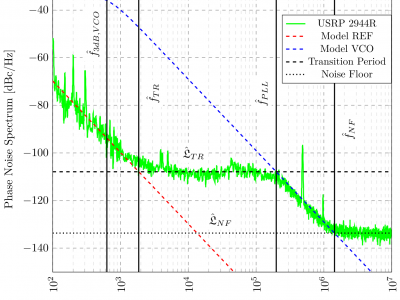
Phase noise is a common hardware impairment, resulting from the frequency instability of voltage-controlled oscillators (VCO). To improve the phase noise performance of a VCO, they are typically connected to a control circuit. This control circuit is known as phase locked loop (PLL). It is commonly used as a frequency synthesizing circuit for the carrier frequency in mobile communication transceivers. Universal Software Radio Peripherals (USRP) are widely used in mobile communication research.
- Categories:
312 Views
Modern automotive embedded systems include a large number of electronic control units (ECU) responsible for managing sophisticated systems such as engine control, ABS brake systems, traction control, and power steering systems. To ensure the reliability and effectiveness of these functions, it is essential to apply rigorous test approaches and standards. The integration of diagnostic functions in automotive embedded systems demands consistent tests and a detailed analysis of data.
- Categories:
173 Views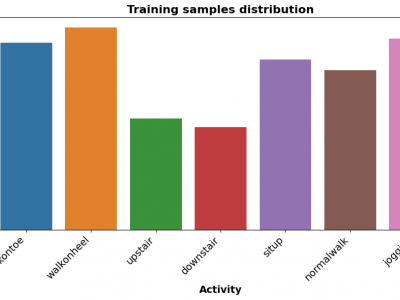
The Human Activity Recognition (HAR) dataset comprises comprehensive data collected from various human activities including walking, running, sitting, standing, and jumping. The dataset is designed to facilitate research in the field of activity recognition using machine learning and deep learning techniques. Each activity is captured through multiple sensors providing detailed temporal and spatial data points, enabling robust analysis and model training.
- Categories:
254 Views
Precise modeling of dynamical systems can be crucial for engineering applications. Traditional analytical models often struggle when capturing real-world complexities due to challenges in system nonlinearity representation and model parameter determination. Data-driven models, such as deep neural networks (DNNs), offer better accuracy and generalization but require large quantities of high-quality data.
- Categories:
159 Views
The file “marine_data.mat” is the data from the marine experiment, including data from different navigation and positioning sensors. The file “lake_data.mat” is the data from the lake experiment, including data from different navigation and positioning sensors.
The meaning and explanation for each column in the file “lake_data.mat” is shown as below:
Acc_x is the x-axis acceleration of the surface vehicle.
Acc_y is the y-axis accelerationof the surface vehicle.
- Categories:
171 Views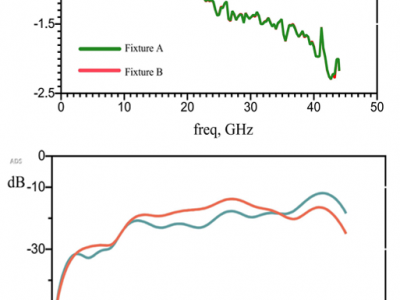
s11 and s21:hows the ADS simulation of 2X-thru, where the S2P files of fixtures A and B are introduced to observe whether fixtures A and B are symmetric. It can be seen from the insertion loss S21 and return loss S11 of the 2X-thru simulation in Fig. 5(c) that the insertion losses of fixtures A and B almost coincide, but the return loss is not completely coincident because of the discontinuous impedance of the transmission line of fixtures A and B at the connection between the coaxial connector and the PCB. In Fig.
- Categories:
153 Views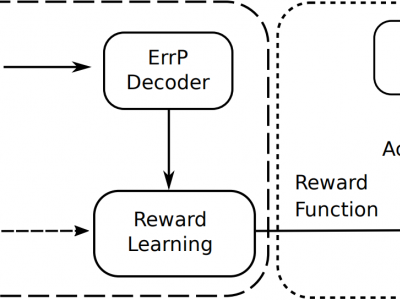
This dataset contains EEG error-related potential signals elicited by humans while observing an AI agent play an atari-based maze game.
- Categories:
166 Views
Active noise control (ANC) aims at reducing a noise source at a listening point by destructive interference with a reversed phase noise emitted by one or more controlling devices. These data are from an active vibration control (AVC) system applied to a wall of the metal box of a cogeneration plant. It makes use of electro-dynamic shakers as controllers and accelerometers as error and reference signals. The algorithm employed for generating the cancelling signals is a single-reference, single-input multiple-output (MIMO) Filtered-X Normalized Least Mean Square (FxNLMS).
- Categories:
126 Views