Machine Learning

Agriculture is the backbone of Mizoram’s state economy as the majority of the people use agriculture and its allied sector as their livelihood. According to the 2011 census, more than 50% of the people are still engaged in agriculture and its related activities. Jhum cultivation or shifting cultivation is the primary farming pattern in the state.
- Categories:
 609 Views
609 Views
The COVID-19 Vaccine Misinformation Aspects Dataset contains 3,822 English tweets discussing COVID-19 vaccine misinformation, collected from Twitter/X between December 31, 2020, and July 8, 2021.
- Categories:
123 Views
This dataset is designed for research on 2D Multi-frequency Electrical Impedance Tomography (mfEIT). It includes:
- Categories:
71 Views
Style Transfer Evaluation Benchmark (StyleBench) in submitted paper "StyleShot: A SnapShot on any Style".
To comprehensively evaluate the effectiveness and generalization ability of style transfer methods, we build StyleBench that covers 73 distinct styles, ranging from paintings, flat illustrations, 3D rendering to sculptures with varying materials. For each style, we collect 5-7 distinct images with variations.
In total, our StyleBench contains 490 images across diverse styles.
- Categories:
18 Views
During the study period, with the help of 292 participants, we were able to collect 599,635 app usage records. Here, we summarize the main characteristics of the participants based on the submitted surveys. 59% of the participants were female and 50% aged between 25 and 34. Participants were from all kinds of educational backgrounds ranging from high school diploma to PhD. In particular, 32% of them had a college degree, followed by 30% with a bachelor's degree. Smartphone was the main device used for connecting to the Internet for 53% of the participants, followed by laptop (25%).
- Categories:
66 Views
The Tsinghua App Usage Dataset is a large-scale mobile application usage dataset collected over one week in one of China’s largest cities. It contains anonymized app usage logs from 1,000 users, capturing detailed information on 2,000 identified apps across 9,800 base stations. Each record includes user ID, timestamp, base station location, app ID, and traffic consumption, allowing for comprehensive analysis of individual and regional mobile usage patterns.
- Categories:
67 Views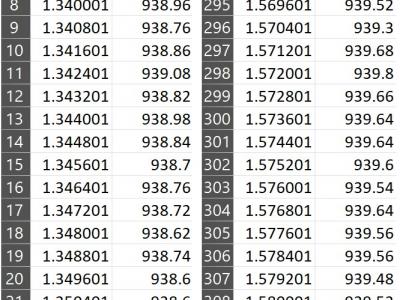
This data set is related to gas sensing, time-series classification. It has three columns: Time, I1, and Target. The Target column refers to the type of gas measured with the following classification:
•1 for Ammonia (NH₃)
•2 for Acetone (C₃H₆O) & Formaldehyde (CH₂O)
The data has been processed in a number of stages for accuracy and consistency. Raw data was first gathered using a Metal Oxide Semiconductor (MOS) sensor. After acquisition, the data were cleaned and processed, such as Savitzky-Golay filtering to remove noise or artifacts and smooth the signal.
- Categories:
164 Views
New technology solutions including tablets and advanced applications exist in modern classrooms across Indonesia but typically they miss the core educational objectives. The process of elementary school children memorizing the emoticon "happy" represents a lack of comprehension while high school students find themselves overwhelmed by IoT data and teachers work to adapt to AI-based educational requirements.
- Categories:
141 Views
The Fuyong dataset records 134 stroke patients who received treatment in the Shenzhen Fuyong People's Hospital between March 1, 2022, and September 31, 2024. Besides, medical records of 435 stroke patients treated in the Affiliated Taizhou People's Hospital of Nanjing Medical University between January 1, 2020, and December 31, 2023, are included in the Taizhou dataset. These two datasets use the pre- and post-thrombolysis of the NIHSS scores as a metric for evaluating the immediate efficacy of the thrombolytic intervention.
- Categories:
222 Views
This dataset supports the LookCursor AI project, which implements eye-tracking-based cursor control using OpenCV and Dlib. The primary file included is shape_predictor_68_face_landmarks.dat, a pre-trained model used to detect and map 68 facial landmarks essential for tracking eye movements. The dataset enables accurate facial feature detection, which is critical for cursor movement based on eye gaze.
- Categories:
131 Views