Education and Learning Technologies


The major language used on social media platforms is primarily dialectal, posing unique challenges for Natural Language Processing. To address this, a large, manually annotated corpus of approximately 30,500 Saudi dialect tweets in the food delivery app domain was introduced. The corpus was annotated with positive, negative, and neutral sentiment categories. Additionally, the existing SauDiSenti lexicon was expanded by 30%, providing an improved resource for sentiment analysis in the Saudi dialect. the corpus and expanded lexicon have been evaluated using machine learning classifiers.
- Categories:
 88 Views
88 Views
Latent fingerprint identification is crucial in forensic science for linking suspects to crime scenes. Latent examiners obtain unique, reliable evidence by revealing hidden prints through advanced techniques. However, latent fingerprints often are partial prints with undesirable characteristics such as noise or distortion. Due to these characteristics, identifying the physical details of a latent fingerprint, known as minutiae, is a complex task. Recent publications found that there are subsets on one minutia in latent fingerprints that, when removed, increase the matching score.
- Categories:
205 Views
The dataset contains Moodle Log Reports of two batches of students. They used Moodle platform for their solo and team activities. The column includes Date, Time, User full name, Affected User, Event Context, Component, Event Name, Description, Origin and IP Address. The sensitive data like User name and IP address are removed in this Draft version dataset. Pivot table is used for filtering the data and visual charts and graphs are applied for understanding the data.
- Categories:
365 Views
IRIC method's data and code are available at this URL.
These data links contain publicly available datasets that can be downloaded directly from their website. Our research on IRIC has validated the performance of the model through these publicly available datasets. Please continue to pay attention.
These data mainly include Emergency Event Data (ALARM) and Education Dataset (Junyi), which can be used for research in causal structure learning, knowledge tracking, and other areas.
- Categories:
67 Views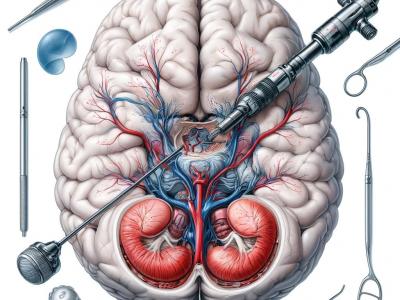
This dataset comprises 1718 annotated images extracted from 29 video clips recorded during Endoscopic Third Ventriculostomy (ETV) procedures, each captured at a frame rate of 25 FPS. Out of these images, 1645 are allocated for the training set, while the remainder is designated for the testing set. The images contain a total of 4013 anatomical or intracranial structures, annotated with bounding boxes and class names for each structure. Additionally, there are at least three language descriptions of varying technicality levels provided for each structure.
- Categories:
418 Views
This study investigates the optimization of cross-course learning paths in e-learning environments, addressing the challenge of navigating vast educational resources and aligning them with diverse learner needs. We propose a novel cross-course learning path planning model that integrates resources from multiple courses to tailor educational experiences to individual learner profiles. The model employs a modified affinity function, the item response theory (IRT), and a knowledge graph to effectively match learners' abilities with material difficulties and prerequisites.
- Categories:
278 Views
Early detection of kidney illness can be achieved by training machine learning algorithms to discover patterns in patient data, such as imaging, test results, and medical history. This will enable rapid diagnosis and start of treatment regimens, which can improve patient outcomes. With 98.97% accuracy in CKD detection, the suggested TrioNet with KNN imputer and SMOTE fared better than other models. This comprehensive research highlights the model's potential as a useful tool in the diagnosis of chronic kidney disease (CKD) and highlights its capabilities.
- Categories:
1199 Views
With the goal of enhancing future views of the Metaverse as an educational tool, this research examines its adoption by higher education institutions through a theoretical lens. The launch of this technology in the higher education sector has occurred relatively recently, yet there have been few efforts to evaluate its impact. The purpose of this research is to examine what variables affect the continuous intention (CI) to utilize the educational Metaverse by combining the technology acceptance model (TAM) with self-determination theory (SDT).
- Categories:
103 Views
Simulation of the matrix-scaled consensus algorithm [1,2] on the network derived from the dataset socfb-Amherst41 [3,4].
References
[1] Trinh, M. H., Vu, D. V., Tran, Q. V., and Ahn, H.-S. "Matrix-scaled consensus." In Proc. of the 61st IEEE Conference on Decision and Control (CDC), pp. 346-351. IEEE, 2022. arXiv preprint arXiv:2204.10723 (2022)
[2] Trinh, M. H., Vu, H. H., Le-Phan, N.-M., and Nguyen, Q. N. "Matrix-Scaled Consensus over Undirected Networks." arXiv preprint arXiv:2303.14751 (2023).
- Categories:
373 Views