Artificial Intelligence


We have obtained data from May 2022 to October 2023 for our suggested framework modelling. This set of data incorporates seasonality-related speech, which we convert into text, Facebook, and Twitter posts. On the whole, 4646 data elements have been acquired, comprising 3716 representing affected individuals and the remainder of 930 representing unaffected individuals, which generated a proportional 4:1 ratio.
- Categories:
 422 Views
422 Views
The existing datasets lack the diversity required to train the model so that it performs equally well in real fields under varying environmental conditions. To address this limitation, we propose to collect a small number of in-field data and use the GAN to generate synthetic data for training the deep learning network. To demonstrate the proposed method, a maize dataset 'IIITDMJ_Maize' was collected using a drone camera under different weather conditions, including both sunny and cloudy days. The recorded video was processed to sample image frames that were later resized to 224 x 224.
- Categories:
360 Views
The SaudiShopInsights dataset is a comprehensive collection of customer reviews in the Arabic language, specifically focusing on the Saudi dialect, within the domains of fashion and electronics. Gathered from various online platforms, this dataset serves as a valuable resource for researchers and practitioners interested in sentiment analysis, natural language processing, and customer behavior studies.
- Categories:
366 Views
The dataset comprises diverse objects detectable by drones during aerial surveys, encapsulating an extensive array of environmental and man-made elements. Encompassing natural entities like trees, water bodies, terrain features, and vegetation, it also incorporates urban objects such as buildings, roads, vehicles, and infrastructure. The dataset delineates distinct categories, encompassing fine-grained details within each classification, catering to the nuances of aerial detection.
- Categories:
186 Views
Scene text detection and recognition have attracted much attention in recent years because of their potential applications. Detecting and recognizing texts in images may suffer from scene complexity and text variations. Some of these problematic cases are included in popular benchmark datasets, but only to a limited extent. In this work, we investigate the problem of scene text detection and recognition in a domain with extreme challenges.
- Categories:
112 Views
Scene text detection and recognition have attracted much attention in recent years because of their potential applications. Detecting and recognizing texts in images may suffer from scene complexity and text variations. Some of these problematic cases are included in popular benchmark datasets, but only to a limited extent. In this work, we investigate the problem of scene text detection and recognition in a domain with extreme challenges.
- Categories:
24 Views
Intelligence and flexibility are the two main requirements for next-generation networks that can be implemented in network slicing (NetS) technology.This intelligence and flexibility can have different indicators in networks, such as proactivity and resilience. In this paper, we propose a novel proactive end-to-end (E2E) resource management in a packet-based model, supporting NetS.
- Categories:
251 Views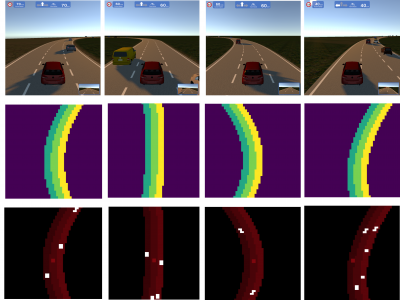
Volkswagen Group of America Innovation and Engineering Center California (VW IECC) is a research facility in Belmont, California working on the future of the mobility. In the recent years exciting developments have happened for the autonomous vehicles. In general, lack of data is the main problem to tackle to solve the task of autonomous driving. One of the important tasks in this topic is the overtaking and lane changes, especially in the highway scenarios.
- Categories:
340 Views
In the contemporary cybersecurity landscape, robust attack detection mechanisms are important for organizations. However, the current state of research in Software-Defined Networking (SDN) suffers from a notable lack of recent SDN-OpenFlow-based datasets. Here we introduce a novel dataset for intrusion detection in Software-Defined Networking named SDNFlow. The dataset, derived from OpenFlow statistics gathered from real traffic, integrates a comprehensive range of network activities.
- Categories:
1250 Views