Artificial Intelligence

Hyperspectral images are represented by numerous
narrow wavelength bands in the visible and near-infrared parts
of the electromagnetic spectrum. As hyperspectral imagery gains
traction for general computer vision tasks, there is an increased
need for large and comprehensive datasets for use as training
data.
Recent advancements in sensor technology allow us to capture
hyperspectral data cubes at higher spatial and temporal reso-
lution. However, there are few publicly available multi-purpose
- Categories:
 103 Views
103 Views
The necessity for strong security measures to fend off cyberattacks has increased due to the growing use of Industrial Internet of Things (IIoT) technologies. This research introduces IoTForge Pro, a comprehensive security testbed designed to generate a diverse and extensive intrusion dataset for IIoT environments. The testbed simulates various IIoT scenarios, incorporating network topologies and communication protocols to create realistic attack vectors and normal traffic patterns.
- Categories:
330 ViewsThis is a lightweight and versatile robustness benchmark built upon the training set of ImageNet-1K. It contains an overall of 50,000 images, divided in 5 components, evenly distributed over 1,000 classes. It assesses the performance of a classification model in five aspects: accuracy on intrinsically difficult images (SuperHard, SH), images with partial information (PartialInfo, PI), robustness against low resolution (LowResolution, LR), adversarial attacks (AdversarialAttack, AA), and speckle noise (SpeckleNoise, SN).
- Categories:
104 Views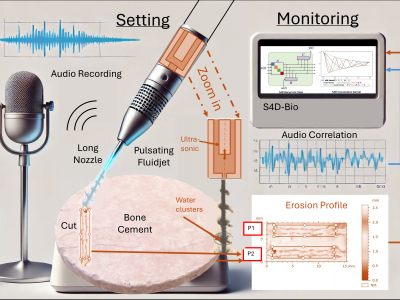
This dataset comprises extensive multi-modal data related to the experimental study of ultrasonically excited pulsating fluid jets used for bone cement removal. Conducted at the Institute of Geonics, Ostrava, Czech Republic, the study explores the effect of varying standoff distances on erosion profiles, under controlled parameters including a fixed nozzle diameter, sonotrode frequency, supply pressure, and robot arm velocity. The dataset includes numerical data representing ablation profiles, captured as a large CSV file, and audio recordings captured using a high-resolution microphone.
- Categories:
201 Views
With the accelerating pace of population aging, the urgency and necessity for elderly individuals to control smart home systems have become increasingly evident. Smart homes not only enhance the independence of older adults, enabling them to complete daily activities more conveniently, but also ensure safety through health monitoring and emergency alert systems, thereby reducing the caregiving burden on families and society.
- Categories:
162 Views
Drafting is a game mode in collectible card games where players build their decks from a restricted pool of cards. Throughout one draft, players are offered a series of selections, from which they must build their deck. Although drafting is a popular game variant in \textit{Magic: The Gathering}, few machine learning models have been developed to learn card selection strategies. We model drafts with a Siamese neural network that is trained on real-world data and predicts human expert selection. Our model learns an embedding space of preferences by comparing cards in the context of a deck.
- Categories:
60 Views
<p>A dataset to detect knowledge conflict.</p>
The dataset contains 90 groups of natural language sentences with contradictions and 10 groups without contradictions, each group containing 5 sentences, usually 3 identical questions and 2 declarative sentences. The Agent should be able to accurately detect the contradictory statements.
- Categories:
27 Views
Please cite the following paper when using this dataset:
Vanessa Su and Nirmalya Thakur, “COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations”, Proceedings of the IEEE 15th Annual Computing and Communication Workshop and Conference 2025, Las Vegas, USA, Jan 06-08, 2025 (Paper accepted for publication, Preprint: https://arxiv.org/abs/2412.17180).
Abstract:
- Categories:
150 Views
Dataset for "SynEL: A Synthetic Benchmark for Entity Linking" paper. The dataset integrates structured information from two primary sources: DBpedia for English, representing a high-resource language environment, and the Russian Public Company Register, a challenging low-resource dataset. Each dataset includes extensive annotations and structured entity links, ensuring high relevance for real-world applications in diverse industries.
- Categories:
277 Views
With multiple large open source datasets, the development of action recognition is rapid. However, we noticed the lack of annotated data of cilvil aircraft pilots, while distribution of whose action can be very different from daily casual activities. After discussion with experienced pilots and experts and close look into standard operation procedure, we present Airline-Pilot-Action (APA) benchmark, containing 5090 RGB and depth images together with corresponding flight computer data.
- Categories:
187 Views