
Twitter2015 and Twitter2017 for Multimodal Aspect-Based Sentiment Analysis (MABSA).
- Categories:
Twitter2015 and Twitter2017 for Multimodal Aspect-Based Sentiment Analysis (MABSA).
Turbulence is a new benchmark and automated testing framework based on the question neighbourhood approach for systematically evaluating the accuracy (the overall rate of correctness across all generated outputs), correctness potential (whether the LLM produces at least one correct output for a given input), and consistent correctness (the model’s ability to consistently produce correct outputs for the same input across successive generations) of instruction-tuned large language models (LLMs) for code generation.
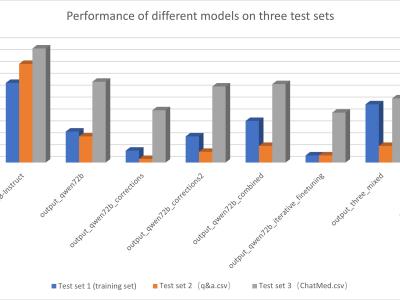
不同模型的效果

The dataset consists of images of Turkish cucumber leaves. These images are collected from the Global Hydroponics Plant located in Katraj, Pune. Image acquisition is carried out using three different smartphones with varying camera specifications, ensuring diversity in image resolution and quality.

The Massachusetts dataset, created using vector data from the OpenStreetMap (OSM) platform, was observed to contain various types of labeling errors. Since the OSM data are continuously updated by volunteer contributors, manual data entry may bring the risk of inconsistency and inaccuracy [20]. Also, the resolution of the images exacerbates labeling errors by contributing to problems such as blurred building boundaries [21].
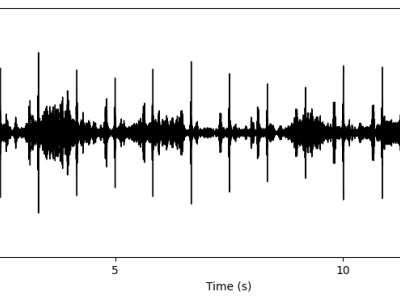
This dataset contains 535 recordings of heart and lung sounds captured using a digital stethoscope from a clinical manikin, including both individual and mixed recordings of heart and lung sounds; 50 heart sounds, 50 lung sounds, and 145 mixed sounds. For each mixed sound, the corresponding source heart sound (145 recordings) and source lung sound (145 recordings) were also recorded. It includes recordings from different anatomical chest locations, with normal and abnormal sounds.
Multimodal MR image synthesis aims to generate missing modality images by effectively fusing and mapping from a subset of available MRI modalities. Most existing methods adopt an image-to-image translation paradigm, treating multiple modalities as input channels. However, these approaches often yield sub-optimal results due to the inherent difficulty in achieving precise feature- or semantic-level alignment across modalities.
This data set includes student responses and expert ratings from the test administrations for the Turkish History course. For each question, the correct answer is assigned a new label, while incorrect answers are labeled as “0”. For 15 questions, there are true-false scores and for 4 questions there are true-partially true-false scores.

The dataset consists of airport specific ground crew and allocation data for four major airports - Kempegowda International Airport (BLR), Rajiv Gandhi International Airport (HYD), Indira Gandhi International Airport (DEL), and Chhatrapati Shivaji Maharaj International Airport (BOM). The tasks, floors and gates, i.e, the tasks and their locations are factual data where as the allocation data is approximately close to realistic demand. The crew demand is synthetically generated.
The Cross-Domain Deception Dataset (CD3) contains frame-level features extracted from video data using OpenFace and OpenPose to support research in deception detection through facial expressions, facial action units, body and hand gestures, and gaze coordinates. Using a commercial off-the-shelf laptop and Microsoft Teams, we collected video data of 45 participants completing mock interviews where they answered questions related to biographical information, academic success, and well-being across two sessions.