*.csv

SynGen6 is a synthetic genomic dataset that encompasses six distinct populations. We utilized Principal Component Analysis (PCA) and ϵ-local differential privacy (LDP) to generate synthetic samples. We then simulated phenotype vectors associated with significant SNPs, mirroring real-world gene-disease associations. We also generated synthetic SNPs to watermark the dataset enabling verification of outsourced computations. Lastly, synthetic relatives were created to support research on kinship inference and family-based genomic analyses.
- Categories:
 89 Views
89 Views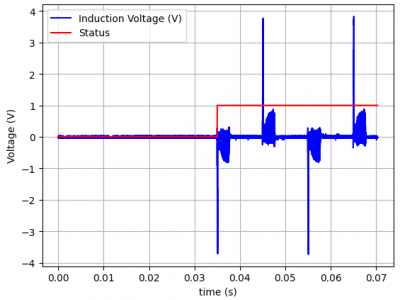
This is an example of a signal from an RCD reading from a 7W Led Lamp load. The data is titled with two status: 0 for normal condition (NC) and 1 for single fault condition (SFC). From the signal, It was evident that the peak voltage fluctuated over a certain time. The signal waveform displayed a positive peak and a negative peak alternatively in a comparable amount of time, while lacking any distinct cosine form or fixed values for the peak voltages. It was discovered through measuring that time period that it had the same frequency of 50 Hz as the source of the input.
- Categories:
48 Views
The TiHAN-V2X Dataset was collected in Hyderabad, India, across various Vehicle-to-Everything (V2X) communication types, including Vehicle-to-Vehicle (V2V), Vehicle-to-Infrastructure (V2I), Infrastructure-to-Vehicle (I2V), and Vehicle-to-Cloud (V2C). The dataset offers comprehensive data for evaluating communication performance under different environmental and road conditions, including urban, rural, and highway scenarios.
- Categories:
1253 Views
Endemic fish species are key components in seafood culinary excursions. Despite the increasing interest in leveraging technology to enhance various seafood culinary activities, there is a shortage of comprehensive datasets containing images of seafood used in artificial intelligence research, mainly those showcasing endemic fish. This research endeavors to bridge this gap by increasing the accuracy of fish recognition and introducing a new dataset comprising images of native fish for application in various machine-learning investigations.
- Categories:
190 Views
The dataset consists of uplink channel gains, downlink channel gains and uplink to downlink channel gains along with corresponding power allocations for uplink users and downlink users across all subcarriers. Additionally, it consists of NOMA decoding order for successful implementation of SIC at NOMA receiver. The number of UL users and DL users are considered as N=M=6, and subcarriers are S=9. Each column in the dataset is a sample for fading channel realization and it should be converted back to the matrix to compute sumrate.
- Categories:
202 Views
A modern Wi-Fi-enabled device (e.g., a smartphone) can spontaneously emit unencrypted and anonymized signals to the environment in search of an access point. This signal is called a probe request. Since it is freely available in the open air, one can build a sensor from a Wi-Fi adapter to capture the signal. Once captured, its signal strength can be measured in the form of a Received Signal Strength Indicator (RSSI).
- Categories:
217 Views
This dataset is a network representation of authors linked to the publications they have authored or co-authored, collected from OpenAlex.org using the free, open-source tool available at https://openalex4nodexl.netlify.app/. It is provided as a CSV flat file, formatted for use with NodeXL, a popular tool for social network analysis.
- Categories:
204 Views
# Top 100 YouTube Channels Dataset
## Overview
This dataset provides comprehensive information about the top 100 YouTube channels based on subscriber count. It offers valuable insights into the most popular content creators on the platform, their performance metrics, and channel details.
## Dataset Contents
The dataset includes the following information for each channel:
- Channel ID
- Title
- Custom URL
- Subscriber Count
- Video Count
- View Count
- Category
- Country
- Categories:
131 Views
Each HistDataX.csv file refers to a set of historical data.
Each column refers to an attribute, including:
Driving distance (km),
Vehicle speed (km/h),
Motor output power (W),
Acceleration padel position (%),
Traffic status (0, 1, 2,…, 4; the bigger, the heavier),
Traffic jam direction (-1 opposite direction, 0 unknown, 1 same direction),
Traffic flow speed (km/h).
The sample rate is 10 Hz.
- Categories:
168 Views
We gathered a total of 1,515 news articles concerning suicide, building jumps, and related incidents from 2019 to 2024. Utilizing sentiment analysis tools, we categorized the data into two groups: positive sentiment words and negative sentiment words. Our primary objective was to examine the relationship between negative sentiment words and other associated terms.
- Categories:
186 Views