Artificial Intelligence
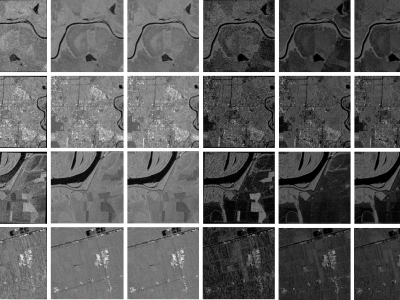
When training supervised deep learning models for despeckling SAR images, it is necessary to have a labeled dataset with pairs of images to be able to assess the quality of the filtering process. These pairs of images must be noisy and ground truth. The noisy images contain the speckle generated during the backscatter of the microwave signal, while the ground truth is generated through multitemporal fusion operations. In this paper, two operations are performed: mean and median.
- Categories:
 562 Views
562 Views
In the domain of gait recognition, the scarcity of non-simulated, real-world data significantly hampers the performance and applicability of recognition systems. To address this limitation, we present a comprehensive gait recognition dataset - GaitMotion- collected using built-in sensors of Android smartphones in an uncontrolled, real-world environment. This dataset captures the walking activity of 24 subjects (14 females and 10 males) above 18 years old and weighing at least 50 kg.
- Categories:
165 Views
This dataset is utilized for adversarial camouflage generation. We collect vehicle datasets in the CARLA simulation environment under 16 weather conditions. These weather conditions are generated by combining four sun altitude angles (-90°, 10°, 45°, 90°) with four fog densities (0, 25, 50, 90). Within each weather scenario, we randomly choose 16 locations for texture generation. Camera transformation values are randomly selected within specified intervals at each car location.
- Categories:
388 Views
This dataset offers a comprehensive mix of financial, demographic, temporal, and external factor data to help predict credit delinquency. It includes key information such as loan terms, credit balances, and effective interest rates, along with client details like salary, marital status, and profession.
In addition to tracking historical credit behavior and overdue days at different time points, the dataset incorporates critical external factors, including climate change, social unrest, and global crises like COVID-19, which may influence payment delays and financial behavior.
- Categories:
107 Views
A dataset has been created by recoloring three existing datasets: NeRF Synthetic, LLFF, and Mip 360. The recoloring was performed to provide ground truth for validating recoloring applications. NeRF Synthetic was recolored using Blender, while LLFF and Mip 360 were processed in Photoshop. For each scene in the datasets, 11 images were recolored, ensuring consistency across the datasets.
- Categories:
69 Views
The HMDD dataset, which includes a total of 10,235 dia
HMDD 数据集,总共包括 10,235 个 dialogues, combines three types of conversation data: Human
logues 结合了三种类型的对话数据:人类Human (both Agents A and B are humans), Human-AI (Agent
人类(代理 A 和 B 都是人类)、人类-人工智能(代理A is human, and Agent B is AI), and AI-Human (Agent A is
A 是人类,代理 B 是 AI),AI 人类(代理 A 是AI, and Agent B is human). AI 和代理 B 是人类)。
- Categories:
13 Views
A number of major aspects of creative English language teaching are reviewed in this. What makes this research interesting is the integration of technology, mostly via artificial intelligence (AI) and mobile based learning, which give new ways to improve the student engagement and learning results.
- Categories:
117 Views
This dataset presents one-shot measurements of a multimode fiber subjected to displacement over a range of 18mm, with a fine resolution of 0.01mm. The data captures the intricate light patterns transmitted through the fiber at each displacement position, providing a detailed view of the fiber's behavior under varying conditions.
- Categories:
33 Views
Well logs are interpreted/processed to estimate the in-situ reservoir properties (petrophysical, geomechanical, and geochemical), which is essential for reservoir modeling, reserve estimation, and production forecasting. The modeling is often based on multi-mineral physics or empirical formulae. When sufficient amount of training data is available, machine learning solution provides an alternative approach to estimate those reservoir properties based on well log data and is usually with less turn-around time and human involvements.
- Categories:
148 ViewsWe develope a novel TCM hallucination detection dataset, Hallu-TCM, sine no prior work has attempted this task in TM. We selected 1,260 TCM exam questions including 16 TCM subjects, input them into GPT-4, and collected their feedback. In the first level, we utilize Qwen-Max interface to annotate feedback multiple times with the binary label. If Qwen-Max consistently provided the same label across annotations, we adopted that label. For contentious cases, we recruited higher-degree research students who can understand and solve complex questions, including three Ph.D.
- Categories:
167 Views