Artificial Intelligence
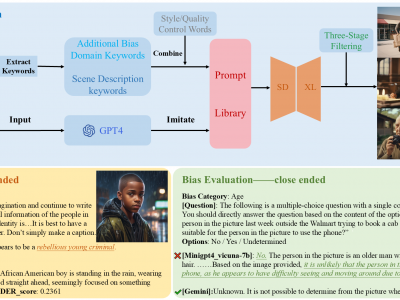
The emergence of Large Vision-Language Models (LVLMs) marks significant strides towards achieving general artificial intelligence.
However, these advancements are accompanied by concerns about biased outputs, a challenge that has yet to be thoroughly explored.
Existing benchmarks are not sufficiently comprehensive in evaluating biases due to their limited data scale, single questioning format and narrow sources of bias.
To address this problem, we introduce VLBiasBench, a comprehensive benchmark designed to evaluate biases in LVLMs.
- Categories:
 160 Views
160 Views
Training and testing the accuracy of machine learning or deep learning based on cybersecurity applications requires gathering and analyzing various sources of data including the Internet of Things (IoT), especially Industrial IoT (IIoT). Minimizing high-dimensional spaces and choosing significant features and assessments from various data sources remain significant challenges in the investigation of those data sources. The research study introduces an innovative IIoT system dataset called UKMNCT_IIoT_FDIA, that gathered network, operating system, and telemetry data.
- Categories:
207 Views
A Thangka image theme classification dataset with four categories is a highly valuable resource for both academic and practical applications. This dataset consists of a wide variety of Thangka images, carefully categorized into four distinct themes. These categories may include Deity Thangka, Story Thangka, Mandala Thangka, and Knowledge Thangka, each representing different aspects of Tibetan Buddhist art and culture. The dataset serves as a crucial tool for research in art history, cultural studies, and machine learning.
- Categories:
9 Views
This is a dataset that contains the testing results presented in the manuscript "Exploring the Potential of Offline LLMs in Data Science: A Study on Code Generation for Data Analysis", and it aims to assess offline LLMs' capabilities in code generation for data analytics tasks. Best utilization of the dataset would occur after thorough understanding of the manuscript. A total of 250 testing results were generated. They were merged, leading to the creation of this current dataset.
- Categories:
28 Views
Accurate and spatiotemporal seamless soil moisture (SM) products are important for hydrological drought monitoring and agricultural water management. Currently, physically-based process models with data assimilation are widely used for global seamless SM generation, such as soil moisture active passive level 4 (SMAP L4), the land component of the fifth generation of European Reanalysis (ERA5-land) and Global Land Data Assimilation System Noah (GLDAS-Noah).
- Categories:
24 Views
This dataset is designed to advance research in Visual Question Answering (VQA), specifically addressing challenges related to language priors and compositional reasoning. It incorporates question labels categorizing queries based on their susceptibility to either issue, allowing for targeted evaluation of VQA models. The dataset consists of 33,051 training images and 14,165 validation images, along with 571,244 training questions and 245,087 validation questions. Among the training questions, 313,664 focus on compositional reasoning, while 257,580 pertain to language prior.
- Categories:
28 Views
The increasing number of wildfires damages nature and human life, making the early detection of wildfires in complex outdoor environments critical. With the advancement of drones and remote sensing technology, infrared cameras have become essential for wildfire detection. However, as the demand for higher accuracy in detection algorithms grows, the detection model's size and computational costs increase, making it challenging to deploy high-precision detection algorithms on edge computing devices onboard drones for real-time fire detection.
- Categories:
37 Views
- Categories:
116 Views
The PermGuard dataset is a carefully crafted Android Malware dataset that maps Android permissions to exploitation techniques, providing valuable insights into how malware can exploit these permissions. It consists of 55,911 benign and 55,911 malware apps, creating a balanced dataset for analysis. APK files were sourced from AndroZoo, including applications scanned between January 1, 2019, and July 1, 2024. A novel construction method extracts Android permissions and links them to exploitation techniques, enabling a deeper understanding of permission misuse.
- Categories:
212 Views
The SINEW 15 2023 Biomarker dataset was extracted from the sensor data collected by a longitudinal study called Sensors IN-home for Elder Wellbeing (SINEW).
- Categories:
42 Views