Artificial Intelligence

This dataset is constructed in a study that addresses the gap between text summarization and content readability for diverse Turkish-speaking audiences. It contains paired original texts and corresponding summaries optimized for different readability levels using the YOD (Yeni Okunabilirlik Düzeyi) formula.
- Categories:
 69 Views
69 Views
Dataset for QoS-aware LLM Routing Experiment.
- Categories:
76 Views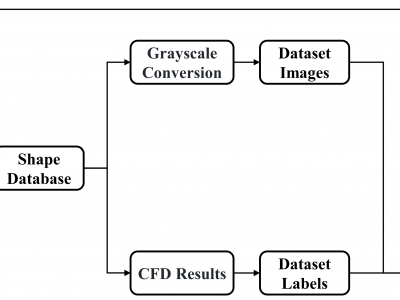
This dataset provides a comprehensive collection of various resources, including the results from Computational Fluid Dynamics (CFD) simulations, the associated CFD processing code, and the dataset along with the source code used for training Convolutional Neural Networks (CNNs). Additionally, it includes data generated by genetic algorithms and the corresponding source code for implementing these algorithms.
- Categories:
151 Views
This dataset is designed for the classification of textual transcriptions of spoken conversations in Shanghai dialect and Mandarin Chinese. It consists of high-quality, manually transcribed texts from natural dialogues, annotated with corresponding language labels (Shanghai dialect: 1, Mandarin: 0).
- Categories:
12 Views
This 3DTeethSegX dataset is a benchmark dataset specifically designed for tooth point cloud completion and segmentation tasks. Built upon the publicly available 3DTeethSeg 2022 MICCAI Challenge dataset, it comprises 1,494 pairs of tooth point clouds and their corresponding tooth images from 38 patients. Each pair includes a partial point cloud (2,048 points) and a complete point cloud (16,384 points).
- Categories:
51 Views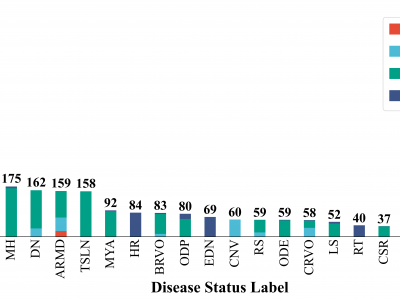
RetinaX dataset is built by selectively combining four publicly available datasets: the STARE dataset, ARIA dataset, RFMiD dataset, and RFMiD 2.0 dataset. It contains a total of 2,514 images and 24 distinct labels, covering nearly all common and rare retinal diseases.
- Categories:
200 Views

The TUROS-TS encompasses 5,357 Google Street View images with 8,775 traffic sign instances covering 9 categories and 28 classes. Three subsets of the dataset were created: test (10%-1050 images 579), validation (20% -1050 images), and training (70% - 3728 images). It is available upon request. If you want to train and test the data set. Please send an email to afef.zwidi@regim.usf.tn
- Categories:
67 ViewsThe TUROS-TS encompasses 5,357 Google Street View images with 8,775 traffic sign instances covering 9 categories and 28 classes. Three subsets of the dataset were created: test (10%-1050 images 579), validation (20% -1050 images), and training (70% - 3728 images). It is available upon request. If you want to train and test the data set. Please send an email to afef.zwidi@regim.usf.tn
- Categories:
27 Views
- Categories:
656 Views