Computer Vision

The LFW, CASIA FaceV5, and KZDD color datasets are used to validate the clustering ability of MKDCSC for low-quality multi-channel visual data. The LFW and CASIA-FaceV5 datasets are the most widely used public color face datasets in the field of face recognition. They are shot under different lighting conditions and complex backgrounds, and many target objects have varying degrees of data defects.
- Categories:
 15 Views
15 Views
We present the SinOCR and SinFUND datasets, two comprehensive resources designed to advance Optical Character Recognition (OCR) and form understanding for the Sinhala language. SinOCR, the first publicly available and the most extensive dataset for Sinhala OCR to date, includes 100,000 images featuring printed text in 200 different Sinhala fonts and 1,135 images of handwritten text, capturing a wide spectrum of writing styles.
- Categories:
493 Views
This dataset consists of 462 field of views of Giemsa(dye)-stained and field(dye)-stained thin blood smear images acquired using an iPhone 10 mobile phone with a 12MP camera. The phone was attached to an Olympus microscope with 1000× objective lens. Half of the acquired images are red blood cells with a normal morphology and the other half have a Rouleaux formation morphology.
- Categories:
952 Views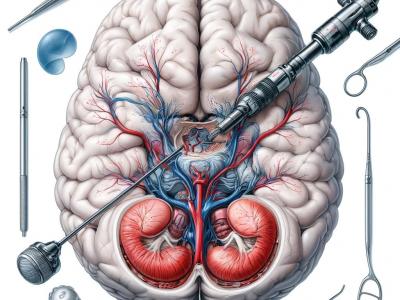
This dataset comprises 1718 annotated images extracted from 29 video clips recorded during Endoscopic Third Ventriculostomy (ETV) procedures, each captured at a frame rate of 25 FPS. Out of these images, 1645 are allocated for the training set, while the remainder is designated for the testing set. The images contain a total of 4013 anatomical or intracranial structures, annotated with bounding boxes and class names for each structure. Additionally, there are at least three language descriptions of varying technicality levels provided for each structure.
- Categories:
410 Views
This is the first multi-view, semi-indoor gait dataset captured with the DAVIS346 event camera. The dataset comprises 6,150 sequences, capturing 41 subjects from five different view angles under two lighting conditions. Specifically, for each lighting condition and view angle, there are six sequences representing normal walking (NM), three sequences representing walking with a backpack (BG), three sequences representing walking with a portable bag (PT), and three sequences representing walking while wearing a coat (CL).
- Categories:
96 Views
Human facial data hold tremendous potential to address a variety of classification problems, including face recognition, age estimation, gender identification, emotion analysis, and race classification. However, recent privacy regulations, such as the EU General Data Protection Regulation, have restricted the ways in which human images may be collected and used for research.
- Categories:
362 Views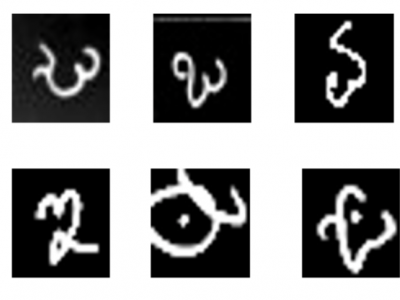
One of the Dravidian language spoken majorly by 60 million people in and around Karnataka state of India is known as Kannada. It is one among 22 scheduled languages of India. Kannada langauge is written in Kannada scriptwhich has its traces back from kadamba script (325-550 AD). There are many languages which were used centuries back and aren’t being used currently whereas Kannada is one such language which is used even today for writing official documents and are being taught at schools which means it is going to be for many years.
- Categories:
180 Views
Speech impairment constitutes a challenge to an individual's ability to communicate effectively through speech and hearing. To overcome this, affected individuals’ resort to alternative modes of communication, such as sign language. Despite the increasing prevalence of sign language, there still exists a hindrance for non-sign language speakers to effectively communicate with individuals who primarily use sign language for communication purposes. Sign languages are a class of languages that employ a specific set of hand gestures, movements, and postures to convey messages.
- Categories:
3730 Views
This dataset acompanies our article titled "Insights into traditional Large Deformation Diffeomorphic Metric Mapping and unsupervised deep-learning for diffeomorphic registration and their evaluation", Computers in Biology and Medicine, 2024. This paper explores the connections between traditional Large Deformation Diffeomorphic Metric Mapping methods and unsupervised deep-learning approaches for non-rigid registration, particularly emphasizing diffeomorphic registration.
- Categories:
262 Views
Dataset of images of dragon fruit plants, collected from different media and taken from a dragon fruit field in Rio Branco, Brazil, with a total of 600 images classified among 300 photos of sick plants, with fish eyes among others and 300 photos of healthy plants. For many of the photos, a simple smartphone
camera was used to capture the images.
- Categories:
993 Views