Image Processing

As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed. To achieve this goal, we introduced a large-sacle (~1.72M frames) traffic sign detection video dataset (CURE-TSD) which is among the most comprehensive datasets with controlled synthetic challenging conditions. The video sequences in the
- Categories:
 5074 Views
5074 Views
This data set contains 50 low resolution (640 x 360) short videos containing a variety real life activities.
- Categories:
271 Views
This Dataset consist of 3Dmodels in Spherical harmonic coefficients andcorresponding shortcut of front view, the SH degree is 80.
- Categories:
108 Views
The modified CASIA dataset is created for research topics like: perceptual image hash, image tampering detection, user-device physical unclonable function and so on.
- Categories:
3912 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed.
- Categories:
3923 Views
This dataset includes all letters from Turkish Alphabet in two parts. In the first part, the dataset was categorized by letters, and the second part dataset was categorized by fonts. Both parts of dataset includes the features mentioned below.
-
72, 20 AND 8 POINT LETTERS
-
UPPER AND LOWER CASES
The all characters in Turkish Alphabet are included (a, b, c, ç, d, e, f, g, ğ, h, ı, i, j, k, l, m, n, o, ö, p, r, s, ş, t, u, ü, v, y, z).
- Categories:
1276 Views
The Dataset
The Onera Satellite Change Detection dataset addresses the issue of detecting changes between satellite images from different dates.
- Categories:
30314 Views
基于波动算法的快速视网膜分割
-------------------------------------------------- -------------------------------------------------- -----------
光电成像与测量技术实验室
地址:中国天津市卫经路92号
邮政编码:300072
电话:+ 86-22-27404535传真:+ 86-22-27404535
- Categories:
304 Views
Pedestrian detection and lane guidance
- Categories:
358 Views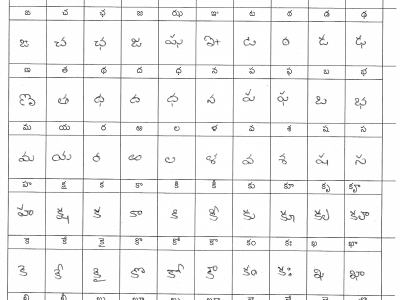
This dataset contains sheets of handwritten Telugu characters separated in boxes. It contains vowel, consonant, vowel-consonant and consonant-consonant pairs of Telugu characters. The purpose of this dataset is to act as a benchmark for Telugu handwritting related tasks like character recognition. There are 11 sheet layouts that produce 937 unique Telugu characters. Eighty three writers participated in generating the dataset and contributed 913 sheets in all. Each sheet layout contains 90 characters except the last which contains 83 characters where the last 10 are english numerals 0-9.
- Categories:
1704 Views