Image Processing

This dataset consists of near-infrared spectral images of eight different varieties of corn seeds, classified as FH759, JL59,JY54,JY205, LH205,XX5, ZY2207, SY81. Each variety contains images of embryonic and endosperm surfaces, with 50 samples per image. The wavelength range is 881-1715 nm.
- Categories:
 233 Views
233 Views
Despite the existence of road image datasets, these datasets predominantly focus on European roads with less variability in traffic and road conditions. To address this limitation, we have developed an image dataset tailored to Indian road conditions, capturing the extensive variations in traffic and environment.
- Categories:
441 Views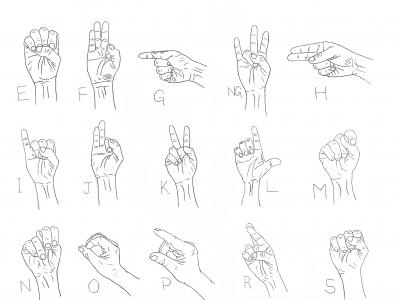
In today’s world, deaf and mute person face many problems in their daily life due to miscommunication as well as misunderstanding. These problems have existed since long ago but are ultimately being solved with the introduction of Hand sign language. There exist many different sign languages such as ASL, ISL, etc. But for regional and low-resource languages like Mizo, the state language of Mizoram, spoken by the northeastern people in India, not much research has been done on the advancement of sign language based on the Mizo language.
- Categories:
402 ViewsIn today’s world, deaf and mute person face many problems in their daily life due to miscommunication as well as misunderstanding. These problems have existed since long ago but are ultimately being solved with the introduction of Hand sign language. There exist many different sign languages such as ASL, ISL, etc. But for regional and low-resource languages like Mizo, the state language of Mizoram, spoken by the northeastern people in India, not much research has been done on the advancement of sign language based on the Mizo language.
- Categories:
182 Views
This dataset consists of 462 field of views of Giemsa(dye)-stained and field(dye)-stained thin blood smear images acquired using an iPhone 10 mobile phone with a 12MP camera. The phone was attached to an Olympus microscope with 1000× objective lens. Half of the acquired images are red blood cells with a normal morphology and the other half have a Rouleaux formation morphology.
- Categories:
1027 Views
This dataset comprises 1718 annotated images extracted from 29 video clips recorded during Endoscopic Third Ventriculostomy (ETV) procedures, each captured at a frame rate of 25 FPS. Out of these images, 1645 are allocated for the training set, while the remainder is designated for the testing set. The images contain a total of 4013 anatomical or intracranial structures, annotated with bounding boxes and class names for each structure. Additionally, there are at least three language descriptions of varying technicality levels provided for each structure.
- Categories:
422 Views
Human facial data hold tremendous potential to address a variety of classification problems, including face recognition, age estimation, gender identification, emotion analysis, and race classification. However, recent privacy regulations, such as the EU General Data Protection Regulation, have restricted the ways in which human images may be collected and used for research.
- Categories:
410 Views
Odia is a classical and popular language in the Indian subcontinent used by more than 50 million people. In spite of its rich history, popularity and usefulness, not much research efforts have been made to achieve high level accuracy in case of Odia OCR. New handwritten alphanumeric character and numeral datasets for Odia are created by our research group@iitbbs and reported here in order to address the paucity of benchmark Odia datasets.
- Categories:
358 Views
This is the pest image dataset. With this data set at hand, scientists or software engineers may create programs capable of recognizing when creatures harm farm produce. This breadth extends not only across different plants but also covers many types of bugs like aphids, leafhoppers, beetles , caterpillars etcetera providing a large diverse pool from which one can train models designed to detect pests. Arranging photos by pest species makes it easy for people looking into them understand what they should expect find.
- Categories:
2233 Views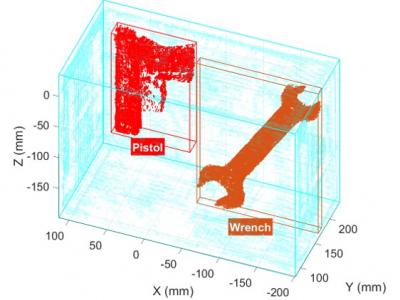
The second set of concealed objects are the pistol and the wrench. The position of the wrench is on the top layer, and the pistol is on the bottom layer. The light blue part is the perimeter of the cardboard box, the red part is the pistol, and the orange part is the wrench. The results of object classification, where the concealed objects are boxed, and the object classification outcomes are displayed beneath the box, all of which are correctly classified.
- Categories:
104 Views