
- Categories:

To investigate SAM's potential in the continual scenario, we construct a benchmark for continual segmentation, called Continual SAM Adaptation Benchmark (CoSAM), which aims to systematically evaluate SAM-related algorithms's performance in the streaming scenarios. Specifically, CoSAM offers a set of 8 tasks covering diverse domains, including industrial defects, medical imaging, and camouflaged objects, to serve as a realistic and effective benchmark for evaluating current methods.

Amid global climate change, rising atmospheric methane (CH4) concentrations significantly influence the climate system, contributing to temperature increases and atmospheric chemistry changes. Accurate monitoring of these concentrations is essential to support global methane emission reduction goals, such as those outlined in the Global Methane Pledge targeting a 30% reduction by 2030. Satellite remote sensing, offering high precision and extensive spatial coverage, has become a critical tool for measuring large-scale atmospheric methane concentrations.

All measurement campaigns are carried out in the standardized meeting room at 260-400 GHz. We categorize samples into two classes: near points Tx1-Tx7 and far points Tx8-Tx23. The measurement setup maintains each static transmitter while positioning the receiver on a computer-controlled stepping rotator. Systematic spatial sampling is achieved through 128 discrete half-wavelength displacements of the receiver assembly, thereby synthesizing a virtual massive multi-antenna array.
Computational experiments within metaverse service ecosystems enable the identification of social risks and governance crises, and the optimization of governance strategies through counterfactual inference to dynamically guide real-world service ecosystem operations. The advent of Large Language Models (LLMs) has empowered LLM-based agents to function as autonomous service entities capable of executing diverse service operations within metaverse ecosystems, thereby facilitating the governance of metaverse service ecosystem with computational experiments.

<p>This comprehensive dataset combines all-sky auroral observations with high-resolution small-scale auroral data and is a resource for space weather research, magnetospheric studies and atmospheric science. The captured all-sky dataset classifies auroral displays into four different morphological types: arcs (smooth, curtain-like structures), folds (folded, undulating structures), radial corona (ray projections from a central point) and hotspots (locally bright regions).

we develop a spatio-spectral-temporal deep learning regression model , termed CASST-Net, which leverages a cosine attention mechanism to enhance feature representation to improve FVC estimation accuracy, can also dynamically adjusted the weighting values of each spectral band in the satellite data based on changes in vegetation physiological characteristics and canopy structure.
we develop a spatio-spectral-temporal deep learning regression model , termed CASST-Net, which leverages a cosine attention mechanism to enhance feature representation to improve FVC estimation accuracy, can also dynamically adjusted the weighting values of each spectral band in the satellite data based on changes in vegetation physiological characteristics and canopy structure.
Laboratory experiments are fundamental to science education, yet resource constraints often limit students’ access to hands-on learning experiences. While object detection technology offers promising solutions for automated material identification and assistance, existing datasets like CABD (21 classes) and Chemical Experiment Image Dataset (7 classes) are limited in scope. We present two comprehensive datasets for laboratory material detection: a Chemistry dataset comprising 1,191 images across 60 classes and a Physics dataset containing 1,749 images across 76 classes.

Geohazards resulting from mining activities must be effectively monitored to mitigate their impact on the environment and human activities. Geohazards such as landslides and collapses caused by open-pit mining are relatively easier to monitor because they are primarily surface-based. In contrast, underground mining disrupts the stress balance in the overlying rock layers, leading to complex settlement patterns, including subsidence basins, cracks, and groundwater depletion.

This is a random subset of FAST data from June 2024. The data has undergone coordinate system transformation and downsampling processing, with a frequency of 1 Hz (The original data includes IMU data from the FAST feed cabin platform sampled at 400 Hz and theoretical trajectory data calculated by the FAST Observatory, both sampled at 1 Hz).
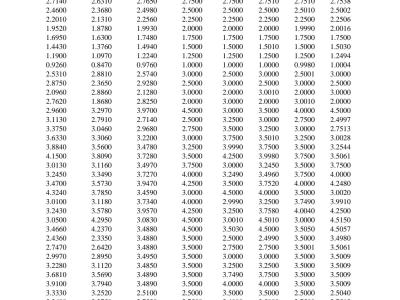
This is the sample data from a switched-capacitor single-input multiple-output (SC-SIMO) converter, which can be utilized to train an artificial neural network (ANN) model. In the dataset, the current references IL3ref, IL2ref, IL1ref, and IL0ref are recorded and applied to the switched-capacitor single-input multiple-output (SC-SIMO) converter, and the introduced inductor currents IL3, IL2, IL1, and IL0 are recorded. During the ANN training process, the inductor currents are considered as the inductor currents references, which are the four inputs of the ANN model.

This dataset includes three types: DEM, land cover data, and high-definition remote sensing images.
Among them, the DEM data has an accuracy of 30 meters and is used to calculate the slope value. The land cover data has an accuracy of 8.98 meters and is located in a field area in southern Taiwan, China, and is used to extract coarse-grained land object types. The high-definition remote sensing data is taken by drones with an accuracy of 0.03 meters and is used for unsupervised classification of land objects.
Ensemble clustering, which integrates multiple base clusterings to enhance robustness and accuracy, is commonly evaluated on over 10 benchmark datasets. These include 6 synthetic datasets (e.g., 3MC,atom,Chainlink,Flame,Jain,wingnut) designed to test algorithms on nonlinear separability and density variations.
This research examines the creation and evaluation of directional eddy current probes designed to identify in-plane waviness in uncured carbon fibre reinforced polymers (CFRP). A new finite element modeling technique was used to precisely replicate current density distortions caused by waviness. A sample made from uncured IM7/8552 prepreg with in-plane waviness on its top layer was produced

This dataset contains detailed technical specifications and market pricing information for power electronic components, specifically MOSFETs and IGBTs from two manufacturers: Wolfspeed and Hitachi. The data was collected through two main methods: manual upload of technical specifications in XML format from the manufacturers' official websites, and real-time market price aggregation using web scraping techniques from the Octopart platform, facilitated by Nexar APIs.

This is a subset of the underwater video-level multi-task learning dataset UVMulti that we created for the paper submission. The complete dataset will be released when the paper is accepted. The file sequence represents the original video sequence, sequence_enh represents the corresponding underwater image enhancement annotation, mask represents the corresponding semantic segmentation annotation, depth represents the sparse depth annotation, and dense_depth represents the dense depth annotation.
The Forbes 2022 Billionaires List dataset contains information about the world's wealthiest individuals, including their net worth, industry, country, and key business ventures. The dataset provides structured details such as rankings, company associations, and financial status, making it useful for various NLP tasks like table-to-text generation, entity recognition, and financial analysis.

Cyberbullying is a growing problem on social media. This dataset helps detect cyberbullying in Bangla by collecting comments from YouTube, Facebook, Instagram, and TikTok. The data is categorized into two types: bullying and non-bullying. It includes various abusive and harmful texts, along with normal conversations. This dataset will help researchers and developers train AI models to automatically identify cyberbullying in Bangla text. The goal is to create better tools to keep online spaces safe for Bangla-speaking users.
This dataset comprises 30 CSV files featuring text-based narratives developed as part of the MOVING (MOuntain Valorisation through INterconnectedness and Green Growth) Horizon 2020 project, which explores 454 value chains across 23 rural regions in 16 European countries. Additionally, it includes 30 JSON files that annotate the keywords within these narratives, linking them to their corresponding Wikidata entries and QIDs.
This dataset comprises 30 CSV files featuring text-based narratives developed as part of the MOVING (MOuntain Valorisation through INterconnectedness and Green Growth) Horizon 2020 project, which explores 454 value chains across 23 rural regions in 16 European countries. Additionally, it includes 30 JSON files that annotate the keywords within these narratives, linking them to their corresponding Wikidata entries and QIDs.
To establish a versatile RSFM adaptable to diverse tasks, RingMoE requires a comprehensive and diverse pre-training dataset that accounts for significant variations in imaging modalities, spatial resolutions, temporal dynamics, geographic regions, and scene complexities. To meet this challenge, we curate RingMOSS, a large-scale multi-modal RS dataset comprising 400 million images from nine satellite platforms, covering a broad spectrum of Earth observation scenarios.

This dataset comprises ten adapted benchmark instances derived from the classical Prodhon dataset, along with one dataset based on a real-world logistics case study. The data are specifically designed to support the evaluation of a bi-objective Green Location Routing Problem (GLRP) model that aims to optimize both economic cost and environmental impact (carbon emissions). Each instance includes detailed information on depot locations and capacities, customer coordinates, demand values, time window settings, service durations, and depot fixed costs.

This dataset contains texture maps, flow field data, and aerodynamic pressure data on the surface of five different vehicle profiles under specific flight conditions, and is suitable for research in aerospace engineering, hydrodynamics, and related fields. The dataset covers the altitude range from 3000 to 4000 meters and the Mach number range from 2.0 to 2.75.