
Preview dataset released.
- Categories:
Preview dataset released.

This dataset contains detailed technical specifications and market pricing information for power electronic components, specifically MOSFETs and IGBTs from two manufacturers: Wolfspeed and Hitachi. The data was collected through two main methods: manual upload of technical specifications in XML format from the manufacturers' official websites, and real-time market price aggregation using web scraping techniques from the Octopart platform, facilitated by Nexar APIs.
This work presents a dataset based on multiple network and service metrics (KPIs and KQIs), the latest providing the E2E conditions of video on demand service. Particularly, the dataset also includes an attack situation where an attacker injects traffic into the network. In total, there are 3600 samples, with different configurations of Physical Resource Blocks and cell gain, from sessions of 60 seconds.
The datasets used for TASLP manuscript. These datasets are widely recognized and validated within the summarization research community, and using these well-established datasets ensures that our results are comparable with the vast majority of related work.In each dataset, we use 80% as the training set, while the remaining 20% as the test data. The range of datasets used for collecting knowledge is also consistent with the above. For the large dataset, we only use a part of it because collecting knowledge is time-consuming.
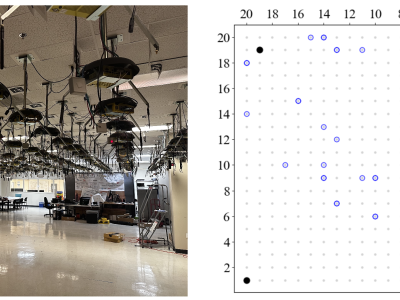
MobRFFI is a WiFi device fingerprinting and re-identification dataset collected in the Orbit testbed facility in July and April 2024. The dataset contains raw IQ samples of WiFi transmissions captured at 25 Msps on channel 11 (2462 MHz) in the 2.4 GHz band, using Ettus Research N210r4 USRPs as receivers and a set of WiFi nodes equipped with Atheros AR5212 chipsets as transmitters. The data collection spans two days (July 19 and August 8, 2024) and includes 12,068 capture files totaling 5.7 TB of data.
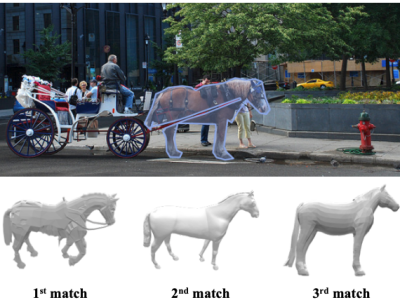
3D-COCO is a dataset composed of MS COCO images with 3D models aligned on each instance. 3D-COCO was designed to achieve computer vision tasks such as 3D reconstruction or image detection configurable with textual, 2D image, and 3D CAD model queries.
3D-COCO is an extension of the original MS-COCO dataset providing 3D models and 2D-3D alignment annotations. We complete the existing MS-COCO dataset with 28K 3D models collected on ShapeNet and Objaverse. By using an IoU-based method, we match each MS-COCO annotation with the best 3D models to provide a 2D-3D alignment.

The dataset provides an end-to-end (E2E) perspective of the performance of 360-video services over mobile networks. The data was collected using a network-in-a-box setup in conjunction with a Meta Quest 2 head-mounted display (HMD) and a customer premises equipment (CPE) to provide 5G connectivity to the glasses (WiFi-native).

Dynamic malicious software detection aims to assess whether executable programs exhibit malicious behavior by thoroughly studying and analyzing their dynamic features. However, many current methodologies insufficiently explore the semantic features of API sequences and instead rely more on mining parameter information during API call processes to enhance detection performance. This leads to issues such as excessive dependence on prior knowledge, larger model parameter sizes, and higher computational complexities.

New capabilities involving sensors, data collection, and data analysis have enabled innovations in how engineered systems are monitored and maintained. Whereas each new evolution of maintenance philosophies has relied upon the current technological state, this research examines potential future capabilities in the field of prognostics and health management (PHM). PHM algorithms for predicting the estimated time to failure for a system are based on sensor data, physical models, or a combination of both.
Register allocation is an important phase in compiler optimization. Often, its resolution involves graph coloring, which is an NP-complete problem. Because of their significance, numerous heuristics have been suggested for their resolution. Heuristic development is a complex process that requires specialized domain expertise. Recently, several machine learning based approaches have been proposed to solve compiler optimization problems.