Digital signal processing

The datasets are composed of the experimental results of my paper submitted to TMM on HELEN and LFW datasets.
- Categories:
 152 Views
152 Views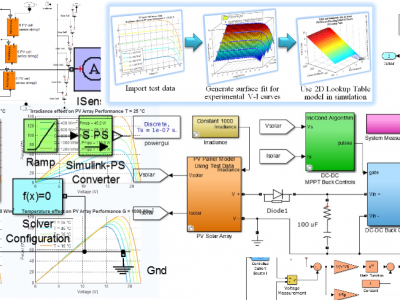
The dataset contains fundamental approaches regarding modeling individual photovoltaic (PV) solar cells, panels and combines into array and how to use experimental test data as typical curves to generate a mathematical model for a PV solar panel or array.
- Categories:
12611 Views
The work starts with a short overview of grid requirements for photovoltaic (PV) systems and control structures of grid-connected PV power systems. Advanced control strategies for PV power systems are presented next, to enhance the integration of this technology. The aim of this work is to investigate the response of the three-phase PV systems during symmetrical and asymmetrical grid faults.
- Categories:
8742 Views
This work presents a novel Anti-Islanding (AI) protection of Photovoltaic (PV) Systems based on monitoring the dc-link voltage of the PV inverter. A PV System equipped with AI protection like frequency relays, a rate of change of frequency (ROCOF) relay, and respectively the proposed dc-link voltage relay is simulated under the conditions of islanding and the detection time for all these AI techniques are compared. The study shows under which conditions our proposed dc-link voltage AI relay is the most efficient.
- Categories:
2611 Views
This work presents a Matlab/Simulink study on anti-islanding detection algorithms for a 100kW Grid-Connected Photovoltaic (PV) Array. The main focus is on the islanding phenomenon that occurs at the Point of Common Coupling (PCC) between Grid-Connected PV System and the rest of the electric power system (EPS) during various grid fault conditions. The Grid-Connected PV System is simulated under the conditions of islanding, and anti-islanding (AI) relay reaction times are measured through the simulation.
- Categories:
2319 Views
This work aims to implement in Matlab and Simulink the perturb-and-observe (P&O) and incremental conductance Maximum Power Point Tracking (MPPT) algorithms that are published in the scientific literature.
- Categories:
3581 Views
This work presents the performance evaluation of incremental conductance maximum power point tracking (MPPT) algorithm for solar photovoltaic (PV) systems under rapidly changing irradiation condition. The simulation model, carried out in Matlab and Simulink, includes the PV solar panel, the dc/dc buck converter and the MPPT controller. This model provides a good evaluation of performance of MPPT control for PV systems.
- Categories:
3766 Views
Costas arrays are permutation matrices that meet the added Costas condition that, when used as a frequency-hop scheme, allow at most one time-and-frequency-offset signal bin to overlap another. Databases to various orders have been available for many years. Here we have a database that is far more extensive than any available before it. A very powerful and easy-to-use Windows utility with a GUI accompanies the database.
- Categories:
2913 ViewsThe dataset stores a random sampling distribution with cardinality of support of 4,294,967,296 (i.e., two raised to the power of thirty-two). Specifically, the source generator is fixed as a symmetric-key cryptographic function with 64-bit input and 32-bit output. A total of 17,179,869,184 (i.e., two raised to the power of thirty-four) randomly chosen inputs are used to produce the sampling distribution as the dataset. The integer-valued sampling distribution is formatted as 4,294,967,296 (i.e., two raised to the power of thirty-two) entries, and each entry occupies one byte in storage.
- Categories:
570 Views
HazeRD is an outdoor scene dataset for benchmarking dehazing algorithms. HazeRD contains 10 different scenes based on the architectural biometrics project. For each scene, the ground RGB images, depth maps, and synthesized hazy images following the atmospheric optics are provided; the hazy images come with five different haze level using real life physical parameters. The main features of HazeRD to other dehazing datasets are: HazeRD focuses on outdoor scenes whereas other datasets provide indoor scenes; and, the synthesis is based on real life parameters.
- Categories:
2587 Views