Artificial Intelligence

One of the key problems in 3D object detection is to reduce the accuracy gap between methods based on LiDAR sensors and those based on monocular cameras. A recently proposed framework for monocular 3D detection based on Pseudo-Stereo has received considerable attention in the community. However, three problems have been discovered in existing practices: (1) relying on a high-performance monocular depth estimator, (2) the generated image suffering from visual holes, deformations, and artifacts, and (3) being difficult to be compatible with geometry-based stereo detectors.
- Categories:
 35 Views
35 Views
This study presents a comprehensive dataset to analyze risk factors associated with cardiovascular disease. The dataset comprises various patient attributes, including gender, age, total cholesterol, HDL (high-density lipoprotein), triglycerides, non-HDL (non-high-density lipoprotein), NIH-Equ-2, and direct LDL (low-density lipoprotein). These attributes comprise 25,991 patient data, robustly representing a large population sample.
- Categories:
599 Views
The BirDrone dataset is compiled by aggregating images of small drones and birds sourced from various online datasets. It comprises 2970 high-resolution images (640x640 pixels), each featuring unique backdrops and lighting conditions. This dataset is designed to enhance machine learning models by simulating real-world scenarios.
Dataset Specifications:
- Categories:
1452 Views
The dataset presents user evaluations for itinerary recommendations generated with three algorithms, PP, PP+TS and PP+TP.
Users evaluated recommendations according to five properties:
- Categories:
149 Views
Speech impairment constitutes a challenge to an individual's ability to communicate effectively through speech and hearing. To overcome this, affected individuals’ resort to alternative modes of communication, such as sign language. Despite the increasing prevalence of sign language, there still exists a hindrance for non-sign language speakers to effectively communicate with individuals who primarily use sign language for communication purposes. Sign languages are a class of languages that employ a specific set of hand gestures, movements, and postures to convey messages.
- Categories:
4769 Views
In deep learning, images are utilized due to their rich information content, spatial hierarchies, and translation invariance, rendering them ideal for tasks such as object recognition and classification. The classification of malware using images is an important field for deep learning, especially in cybersecurity. Within this context, the Classified Advanced Persistent Threat Dataset is a thorough collection that has been carefully selected to further this field's study and innovation.
- Categories:
1876 Views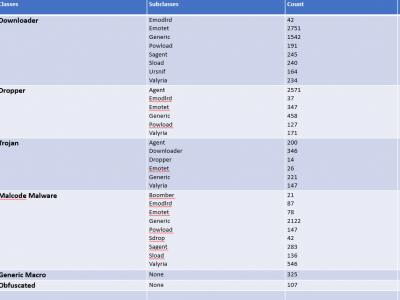
Microsoft contains a productive tool known as MS Office but the inclusion of VBA Macros inside the MS Office for automation purposes makes it a way for attackers to perform malicious activities. To get an up-to-date dataset, the research regarding VBA macros is still working to find efficient ways to detect it. To perform analysis, the dataset is required which is publically harder to find. To overcome this issue, a dataset is created from VirusTotal, VirusShare, Zenodo, Malware Bazaar, Github and InQuest Labs.
- Categories:
1194 Views
The networks are stored under the data/ folder, one file per network. The filename should be <network>.csv.
One line per interaction/edge.
Each line should be: user, item, timestamp, state label, comma-separated array of features.
First line is the network format.
User and item fields can be alphanumeric.
Timestamp should be in cardinal format (not in datetime).
State label should be 1 whenever the user state changes, 0 otherwise. If there are no state labels, use 0 for all interactions.
- Categories:
17 Views
The Sketchy images refer to hand-drawn drawings, while SCIST are those with unclear or weak semantic information, represent a distinctive cases from natural scenes.The primary objective of this dataset is to facilitate the style transfer, whether originating from manual sketches or digital renderings, into enriched and artistically embellished counterparts through the utilization of software.
- Categories:
198 Views
- Categories:
511 Views