Artificial Intelligence

Existing datasets of infrared and visible images only contain few extreme scenes, we construct a dataset of images with haze based on the M3FD dataset. We pick 450 aligned image pairs from M3FD dataset and synthesize hazy visible images using the ASM. Due to the unique imaging principle of infrared images, rarely affected by haze, there is no need to do additional process for infrared images. Finally, a dataset named MHS has been released, which contains 450 pairs of images in hazy conditions.
- Categories:
 67 Views
67 Views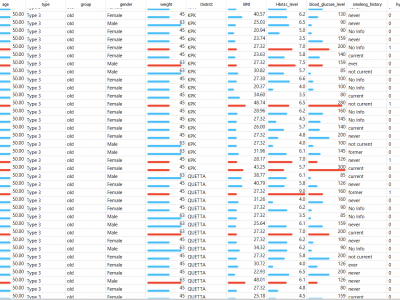
data have 16 features with 1 target value
Scope: Primarily focused on diabetes-related information.
Data Size: Contains a substantial volume of records.
Variables: Likely includes patient demographics, medical history, lab results, medications, treatments, and outcomes.
Temporal Range: Time span covered by the dataset may vary.
Privacy Measures: Anonymized to protect patient identities.
Ethical Considerations: Collected and shared adhering to ethical guidelines.
- Categories:
1697 Views
This dataset contains RGB+D videos and skeleton data for human behavior. The behavior data is captured by 3 Microsoft Kinect V2 cameras from 40 human subjects, with a total of 56,880 samples containing 60 categories totaling 4 million frames, where the maximum frame for all samples is 300. 25 joints are recorded for each body skeleton. The dataset provides two original settings, namely two evaluation protocols, Cross-Subject (Xsub) and Cross-View (Xview). In Xsub protocol, the training set contains 40,320 samples from 20 subjects, and the remaining 16,560 samples are used for testing.
- Categories:
1 Views
The research team conducted logistic and Cox regression according to the behavioral data of gastroesophageal reflux disease patients who had long been drinking caffeinated coffee drinks, and determined the sensitivity and mathematical rationality of AI prediction model in behavioral science, which can support the research team to build a deep learning neural network and complete the prediction of gastrointestinal tract involvement.
- Categories:
157 Views
- Categories:
3 Views
We conducted a retrospective collection, covering 167 children who were examined and treated at the Children's Hospital of Chongqing Medical University from March 12, 2014 to January 7, 2022, with a total of 1634 IRI image sequences. This study has been registered with the Chinese Clinical Trial Registry, registration number ChiCTR2200058971, and complied with the provisions of the Declaration of Helsinki (DoH). The study was approved by the Institutional Ethical Review Board (document number 2022,69), and a waiver of informed consent was obtained.
- Categories:
184 Views
The Deepfake-Synthetic-20K dataset significantly contributes to digital forensics and deepfake detection research. It comprises 20,000 high-resolution, synthetic human face images generated using the advanced StyleGAN-2 architecture. This dataset is designed to support the development and evaluation of machine-learning models that can differentiate between real and artificially synthesized human faces. Each image in the dataset has been meticulously crafted to ensure a diverse representation of age, gender, and ethnicity, reflecting the variability seen in global human populations.
- Categories:
1150 Views
SeaIceWeather Dataset
This is the SeaIceWeather dataset, collected for training and evaluation of deep learning based de-weathering models. To the best of our knowledge, this is the first such publicly available dataset for the sea ice domain. This dataset is linked to our paper titled: Deep Learning Strategies for Analysis of Weather-Degraded Optical Sea Ice Images. The paper can be accessed at: https://doi.org/10.1109/jsen.2024.3376518
- Categories:
318 Views
<p>Mixed critical applications are real-time applications that have a combination of both high and low-critical tasks. Each task set has primary tasks and two backups of high-critical tasks. In the work carried out, different synthetic workloads and case studies are used for extracting the schedule and overhead data on a real-time operating system. The utilization of the task sets lies between 0.7 to 2.4.The Linux kernel is recompiled with Litmus-RT API to monitor the scheduling decisions and also measure the overheads incurred.
- Categories:
169 Views
the first digitalized mammogram dataset for breast cancer in Saudi Arabia, depend on the BI-RADS categories, to solve the availability problem of local public datasets by collecting, categorizing, and annotating mammogram images, supporting the medical field by providing physicians with different diagnosed cases especially in Saudi Arabia
- Categories:
955 Views