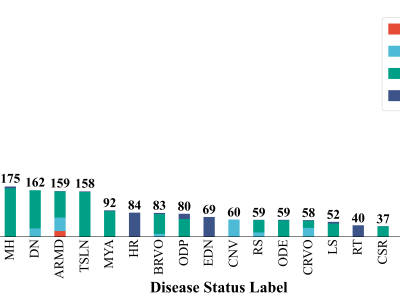
RetinaX dataset is built by selectively combining four publicly available datasets: the STARE dataset, ARIA dataset, RFMiD dataset, and RFMiD 2.0 dataset. It contains a total of 2,514 images and 24 distinct labels, covering nearly all common and rare retinal diseases.
- Categories: