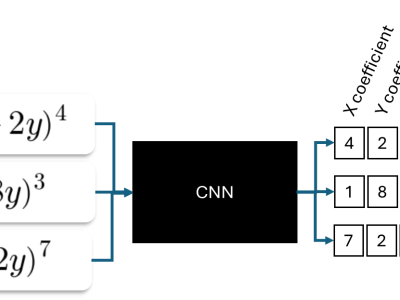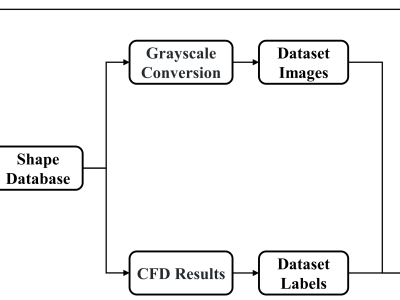
This dataset provides a comprehensive collection of various resources, including the results from Computational Fluid Dynamics (CFD) simulations, the associated CFD processing code, and the dataset along with the source code used for training Convolutional Neural Networks (CNNs). Additionally, it includes data generated by genetic algorithms and the corresponding source code for implementing these algorithms.
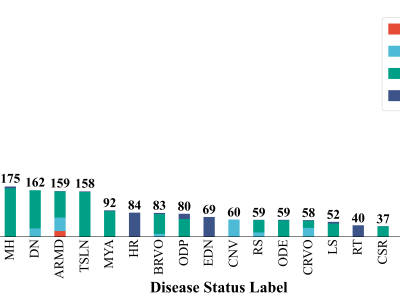
- Categories: