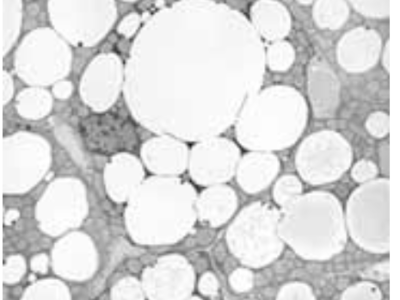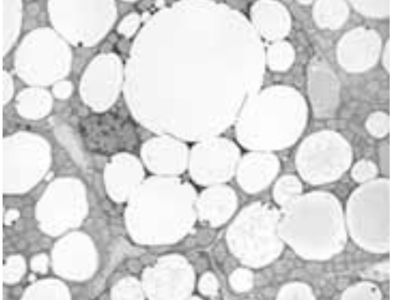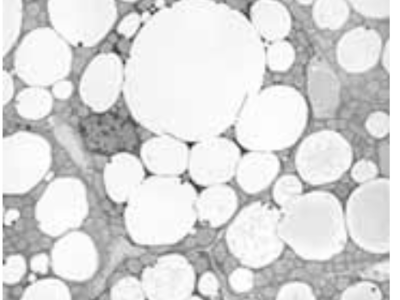
This data provides a comprehensive collection of air quality and meteorological data from several large cities in India. With 1,410 records, it includes key characteristics like the Air Quality Index (AQI) according to both U.S. and China standards, temperature, atmospheric pressure, humidity, wind speed, wind direction, and timestamps.
- Categories: