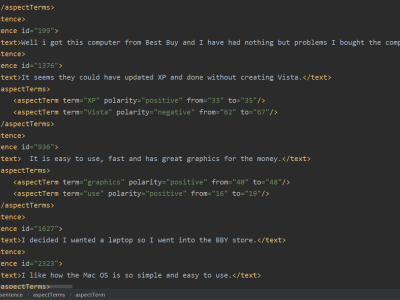
A Chinese dataset for table-to-text generation named WIKIBIOCN which inculeds 33,244 biography sentences with related tables from Chinese Wikipedia (July 2018).
The dataset is divided into training set (30,000), verification set (1000) and test set (2,244).
- Categories: