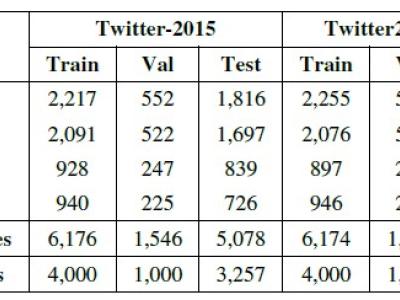
The data is derived from 22,898 comments on driverless and human driving obtained by crawler technology on China's Weibo and XiaoHongshu platforms from May 1 to August 31, 2024. The main data formats are xlsx, py, txt, json and so on. The files in py format are script files, which are used to process data. The dataset was eventually used for topic mining, sentiment analysis, and more on Chinese users' comments on driverless and human driving.
- Categories: