*.csv

The synthetic data is generated loosely following the concepts developed by Skomedal and Deceglie (2020)
- Categories:
 241 Views
241 Views
The dataset is based on the latent faults detected by the popular OSS static code analysis tool, sonarQube Community Edition. The dataset is populated using the latent faults found in popular Java software from the open source repository GitHub . This dataset was specifically developed to identify the significant latent faults that affect the reliability of Java programs. This dataset can be used in its current form to conduct experiments with machine learning algorithms and to infer new reliability characteristics of Java programs. Please refer to the documents associated with sona
- Categories:
21 Views
Classifying the driving styles is of particular interest for enhancing road safety in smart cities. The vehicle can assist the driver by providing advice to increase awareness of potential dangers. Accordingly, dissuasive measures, such as adjusting insurance costs, can be implemented. The service is called Pay-As-You-Drive insurance (PAYD), and to address it, the paper introduces a method for constructing a database of simulated driver behaviors using the Simulation of Urban MObility Simulation of Urban MObility (SUMO) simulator.
- Categories:
389 Views
This data reflects the prevalence and adoption of smart devices. The experimental setup to generate the IDSIoT2024 dataset is based on an IoT network configuration consisting of seven smart devices, each contributing to a diverse representation of IoT devices. These include a smartwatch, smartphone, surveillance camera, smart vacuum and mop robot, laptop, smart TV, and smart light. Among these, the laptop serves a dual purpose within the network.
- Categories:
1976 Views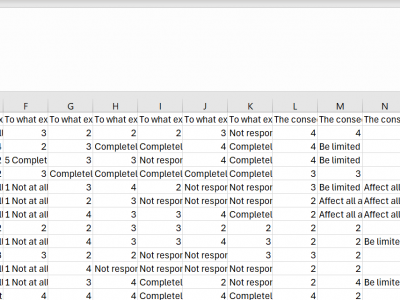
This dataset focuses on the redevelopment and psychometric evaluation of the Adversity Response Profile for Indian Higher Education Institution (ARP-IHEI) students, emphasizing its importance in understanding how individuals respond to adversity. The data were gathered from a sample of 122 second year students at school of computing, MIT Art, Design and Technology University. The psychometric properties were rigorously examined using factor analysis.
- Categories:
67 Views
The rise in Generative Artificial Intelligence technology through applications like ChatGPT has increased awareness about the presence of biases within machine learning models themselves. The data that Large Language Models (LLMs) are trained upon contain inherent biases as they reflect societal biases and stereotypes. This can lead to the further propagation of biases. In this paper, I establish a baseline measurement of the gender and racial bias within the domains of crime and employment across major LLMs using “ground truth” data published by the U.S.
- Categories:
443 Views
This database is from a family of studies about the user-perceived quality and functional suitability of DEMO's Process and Fact Models. It includes three different samples. Sample 1 consists of the results from a group of professionals within the urban appraisal area. Sample 2 consists of the results from a group of health professionals. Finally, Sample 3 includes the results from a group of students trained in the DEMO standard.
- Categories:
64 Views
Recently, contactless hand biometrics authentication has become increasingly popular among biometric researchers. These systems offer several advantages over traditional hand identification systems, including ease of capture and affordability, as they do not require the user’s hand to make direct contact with the sensor.
The Mobile Hand Biometrics (MHB) dataset includes images of fingerprint, palmprint, and hand geometry. These images are captured with a mobile camera without any physical contact, with no lighting conditions, and in free positions.
- Categories:
185 Views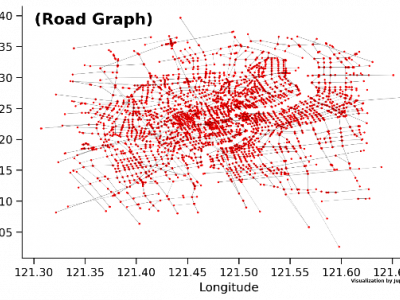
The SH_traffic dataset presents comprehensive traffic speed data for the Shanghai urban area, collected over a period from January 25, 2022, to February 9, 2022. The dataset encompasses a square area of 900 km² and consists of 4,500 graph nodes representing road intersections across the city. The dataset includes traffic speed information recorded at regular intervals, along with related data such as geographical entity attributes and relationships between entities within the road network.
- Categories:
153 Views
- Categories:
132 Views