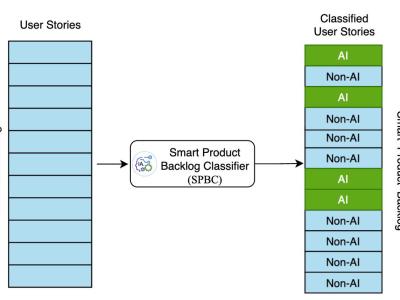
Smart-Product-Backlog: User Stories Classification
- Citation Author(s):
-
Mauricio Gaona-Cuevas
 (Universidad del Valle)
Fredy H. Vera-Rivera
(Universidad Francisco de Paula Santander)
Victor Bucheli Guerrero
(Universidad del Valle)
(Universidad del Valle)
Fredy H. Vera-Rivera
(Universidad Francisco de Paula Santander)
Victor Bucheli Guerrero
(Universidad del Valle)
- Submitted by:
- Fredy Vera-Rivera
- Last updated:
- DOI:
- 10.21227/8tq7-ve62
- Data Format:
 651 views
651 views
- Categories:
- Keywords:
Abstract
The dataset includes 22 projects and 1680 user stories, with the aim of classifying these stories into those suitable for AI implementation and those not recommended for AI implementation. The labeling was done in a group, reaching a consensus on each user story in each project, determining whether it is susceptible to being developed with AI. Thus, each user story was evaluated and assigned a value of 1 if it was considered suitable for AI implementation (this label was named AI), and a value of 0 if it was not (this label was named not-AI). In cases of ambiguity regarding the classification of a US, the topic was researched, then discussed, and a consensus was sought to make an informed decision.
Instructions:
The data set contains 22 projects, in each project each sheet has two columns, the description and a number 1 or 0. The ones with 1 are the ones that are recommended for implementation with IA.







very good dataset
good dataset