Artificial Intelligence

An experimental setup is developed in which shape memory alloy actuator is working againt a linear tension spring as a bias mechanism. The experimental data is collected via microcontroller-based embedded system for training and validation of a self-sensing approach for a shape memory alloy actuator. The provided dataset includes 'electrical power' in watt that is applied to actuate a spring-biased shape memory alloy actuator. measured 'electrical resistance' in ohm, resulting 'displacement' in mm and 'time' stamps in second.
- Categories:
 88 Views
88 Views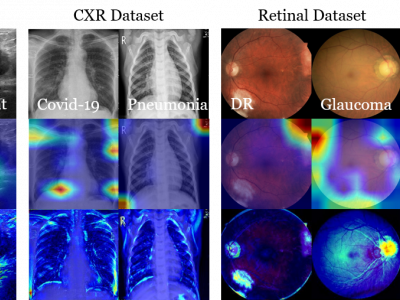
Modern deep neural networks are overparameterized and thus require data augmentation techniques to prevent over-fitting and improve generalization ability. Generative adversarial networks (GANs) are famous for generating visually realistic images. However, the generated images lack diversity and have uncertain class labels. On the other hand, recent methods mix labels proportionally to the salient region.
- Categories:
832 Views
This dataset contains precomputed MS-COCO and Flickr30K Faster R-CNN image features, which are all the data needed for reproducing the experiments in "Stacked Cross Attention for Image-Text Matching", our ECCV 2018 paper. We use splits produced by Andrej Karpathy.
- Categories:
69 Views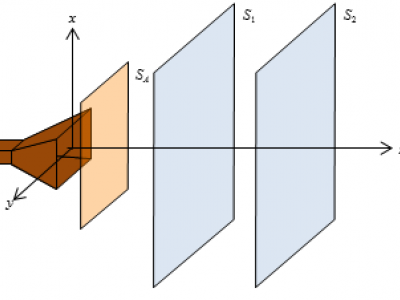
The ultrasound video data were collected from two sets of neck ultrasound videos of ten healthy subjects at the Ultrasound Department of Longhua Hospital Affiliated to Shanghai University of Traditional Chinese Medicine. Each subject included video files of two groups of LSCM, LSSCap, RSCM, and RSSCap. The video format is avi.
The MRI training data were sourced from three hospitals: Longhua Hospital, Shanghai University of Traditional Chinese Medicine; Huadong Hospital, Fudan University; and Shenzhen Traditional Chinese Medicine Hospital.
- Categories:
579 Views
This paper introduces a new dataset named CSED, designed for Chinese cybersecurity ED. The dataset has collected approximately 18,000 news articles related to cybersecurity. We have drawn on the classification definitions of cybersecurity event types from the CAISE [38] , defining two event types: Attack and Vulnerability, and further subdividing them into nine sub-event types: Data Breach, Phishing, Ransom, DDoS Attack, Malware, Supply Chain, Vulnerability Impact, Vulnerability Discovery, and Vulnerability Patch.
- Categories:
426 Views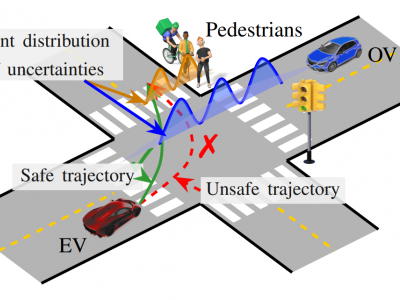
This paper develops a correct-by-design controller for an autonomous vehicle interacting with opponent vehicles with unknown intentions. We define an intention-aware control problem incorporating epistemic uncertainties of the opponent vehicles and model their intentions as discrete-valued random variables. Then, we focus on a control objective specified as belief-space temporal logic specifications. From this stochastic control problem, we derive a sound deterministic control problem using stochastic expansion and solve it using shrinking-horizon model predictive control.
- Categories:
366 Views
This dataset contain the pulse responses of the Tow-Thomas filter circuit, CSTV filter circuit and the four-op-amp biquadratic filter circuit. The test excitation is a 10 us pulse signal with an amplitude of 5 V and a frequency of 5 kHZ that exhibits abundant frequency components. By observing the pulse response, the sampling frequency is set to 5 MHz and the number of sampling points for each sample is fixed at 1000 in Case 1. PSPICE is applied for circuit simulation to set up the circuit fault according to the range of fault component parameter values.
- Categories:
136 Views
In this dataset we release the data of a sequence of boxes that go through a physical binary sorter that acts as a load balancer between warehouses. This particular physical binary sorter works in real-time operating 4.5 million boxes per year. This is a particular example for a company with hundreds of \textit{physical binary sorters} that are central to the internal logistics of the business.
- Categories:
753 Views
As the world increasingly becomes more interconnected, the demand for safety and security is ever-increasing, particularly for industrial networks. This has prompted numerous researchers to investigate different methodologies and techniques suitable for intrusion detection systems (IDS) requirements. Over the years, many studies have proposed various solutions in this regard, including signature-based and machine learning (ML)-based systems. More recently, researchers are considering deep learning (DL)-based anomaly detection approaches.
- Categories:
346 Views
This dataset comprises high-resolution imaging data of biological porcine, clinically approved porcine and bovine, and chick embryo heart tissues. The dataset includes comprehensive anatomical and structural details, making it valuable for research in cardiovascular biology, tissue engineering, and computational modeling. The porcine and bovine heart samples are clinically approved, ensuring relevance for translational and preclinical studies. The chick embryo heart data provides insights into early cardiac development.
- Categories:
105 Views