Artificial Intelligence

This data set has been collected from a custom built battery prognostics testbed at the NASA Ames Prognostics Center of Excellence (PCoE). Li-ion batteries were run through 3 different operational profiles (charge, discharge and Electrochemical Impedance Spectroscopy) at different temperatures. Discharges were carried out at different current load levels until the battery voltage fell to preset voltage thresholds. Some of these thresholds were lower than that recommended by the OEM (2.7 V) in order to induce deep discharge aging effects.
- Categories:
 3792 Views
3792 Views
With the progress made in speaker-adaptive TTS approaches, advanced approaches have shown a remarkable capacity to reproduce the speaker’s voice in the commonly used TTS datasets. However, mimicking voices characterized by substantial accents, such as non-native English speakers, is still challenging. Regrettably, the absence of a dedicated TTS dataset for speakers with substantial accents inhibits the research and evaluation of speaker-adaptive TTS models under such conditions. To address this gap, we developed a corpus of non-native speakers' English utterances.
- Categories:
339 Views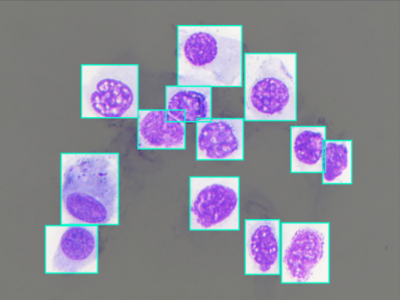
Nasal Cytology, or Rhinology, is the subfield of otolaryngology, focused on the microscope observation of samples of the nasal mucosa, aimed to recognize cells of different types, to spot and diagnose ongoing pathologies. Such methodology can claim good accuracy in diagnosing rhinitis and infections, being very cheap and accessible without any instrument more complex than a microscope, even optical ones.
- Categories:
856 Views
Visual saliency prediction has been extensively studied in the context of standard dynamic range (SDR) display. Recently, high dynamic range (HDR) display has become popular, since HDR videos can provide the viewers more realistic visual experience than SDR ones. However, current studies on visual saliency of HDR videos, also called HDR saliency, are very few. Therefore, we establish an SDR-HDR Video pair Saliency Dataset (SDR-HDR-VSD) for saliency prediction on both SDR and HDR videos.
- Categories:
403 Views
QiandaoEar22 is a high-quality noise dataset designed for identifying specific ships among multiple underwater acoustic targets using ship-radiated noise. This dataset includes 9 hours and 28 minutes of real-world ship-radiated noise data and 21 hours and 58 minutes of background noise data.
- Categories:
1072 Views
This database contains Synthetic High-Voltage Power Line Insulator Images.
There are two sets of images: one for image segmentation and another for image classification.
The first set contains images with different types of materials and landscapes, including the following landscape types: Mountains, Forest, Desert, City, Stream, Plantation. Each of the above-mentioned landscape types consists of 2,627 images per insulator type, which can be Ceramic, Polymeric or made of Glass, with a total of 47,286 distinct images.
- Categories:
653 Views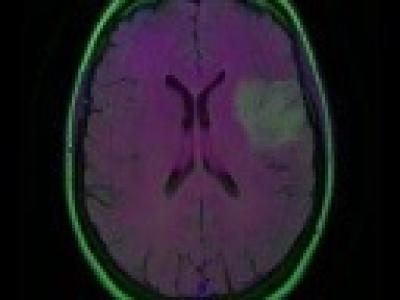
LGG Segmentation Dataset
- Categories:
976 Views
This a Lightning arrester point cloud dataset, using TXT documents to save, each file format is (8192, 7), 8192 means each file has 8192 points, where 1-3 columns are spatial dimensions, 4-6 columns are color information, and the last column is the label information of lightning arrester parts segmentation. It can be used to finished pointcloud segmention task.
- Categories:
69 Views
The Landsat 8 imagery, sourced from USGS Earth Explorer, covers diverse regions like the northeastern USA snow region, Brazilian forests, UAE deserts, and Indian zones (northern, central, and southern) from 2018 to 2023, capturing long-term trends and seasonal changes. The dataset, including bands B4, B5, and B10 with 30-meter resolution from LANDSAT/LC08/C02/T1\_TOA imagery, is crucial for accurate LST and emissivity prediction models. These bands capture vital land surface properties like vegetation health, moisture, and thermal characteristics, enhancing model reliability.
- Categories:
31 Views
While picking robots aim to address this, the complex growth environment poses challenges in identifying and locating fruits due to factors like light and leaf occlusion. This study focuses on designing a recognition and localization method tailored to the natural growth conditions of melons and fruits, aiming to provide precise positional information for effective harvesting. Leveraging GTR-Net and binocular stereo vision, the proposed technology integrates a lightweight backbone network with Ghost bottleneck and TCSPG modules.
- Categories:
101 Views