Artificial Intelligence

Real-time tracking of electricians in distribution rooms is essential for ensuring operational safety. Traditional GPS-based methods, however, are ineffective in such environments due to complex non-line-of-sight (NLOS) conditions caused by dense cabinets and thick walls that obstruct satellite signals. Existing solutions, such as video-based systems, are prone to inaccuracies due to NLOS effects, while wearable devices often prove inconvenient for workers.
- Categories:
 19 Views
19 Views
This dataset contains anonymized responses from 600 Egyptian citizens collected in March 2025 to assess public perceptions of artificial intelligence (AI) and deepfake technologies used in the animation of ancient pharaonic statues and symbols. The survey was conducted as part of a broader research study titled "Animating the Sacred: The Ethical and Cultural Implications of AI-Powered Awakening of Pharaonic Symbols Using Deepfake Techniques."
- Categories:
196 Views
The diameter of the rivet hole is 5mm. In the experiments at the Cooperative Institute, the AE sensor spacing was set to 130mm, where the centers of sensor 1 and sensor 2 were 90mm from each end of the test piece. The waveform flow data obtained in the experiment only retained the information from 30 minutes before the crack initiation to the fracture of the test piece, and the image data of the test piece during this period were recorded.
- Categories:
15 Views
Droidware is an Android malware dataset developed at the Cybersecurity Lab, GLA University, India. It comprises 253,527 applications, including 129,950 benign and 123,577 malicious samples. The dataset captures 68 features extracted from function call graphs, permissions, and Java source code, providing a comprehensive view of Android malware behavior. This latest and up-to-date dataset supports the training of AI-based malware detection models, aiding in the development of robust malware classification and threat mitigation strategies for cybersecurity research.
- Categories:
44 Views
The rapid diffusion and steep concentration gradients of ship exhaust plumes create substantial challenges in velocity field estimation and quantification. To address this limitation, this study develops FluentFluid, the first large-scale optical flow dataset specifically designed for plume motion analysis, as a standardized training benchmark. A novel deep optical flow network architecture guided by grayscale attention mechanisms is proposed. The architecture adopts a dual enhancement strategy through Effective Grayscale Pixels (EGPs) and Grayscale Attention Weights.
- Categories:
5 Views
To establish comprehensive training data for fluid optical flow estimation, we developed a simulated ship emission dataset called FluentFluid. This dataset was generated through computational fluid dynamics simulations using ANSYS Fluent software, with focus on ship exhaust plume modeling. The synthesis pipeline began with the construction of a physical model of ship stack exhaust systems, followed by fluid motion simulation under controlled parametric variations, including exit velocity, stack position, turbulence intensity, and ambient wind conditions.
- Categories:
1 Views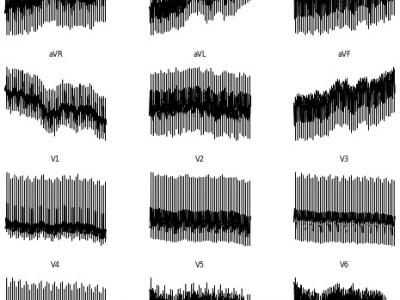
<p>Electrocardiogram (ECG) interpretation is critical for diagnosing a wide range of cardiovascular conditions. To streamline and accelerate the development of deep learning models in this domain, we present a novel, image-based version of the PTB Diagnostic ECG Database tailored for use with convolutional neural networks (CNNs), vision transformers (ViTs), and other image classification architectures. This enhanced dataset consists of 516 grayscale .png images, each representing a 12-lead ECG signal arranged as a 2D matrix (12 × T, where T is the number of time steps).
- Categories:
133 Views
The Travel Recommendation Dataset is a comprehensive dataset designed for building and evaluating conversational recommendation systems in the travel domain. It includes detailed information about users, destinations, and ratings, enabling researchers and developers to create personalized travel recommendation models. The dataset supports use cases such as personalizing travel recommendations, analyzing user behavior, and training machine learning models for recommendation tasks.
- Categories:
37 Views
This dataset compilation brings together four significant traffic network datasets from California's transportation monitoring systems: METR-LA, PEMS-BAY, PEMS04, and PEMS08. The METR-LA dataset is collected from the traffic monitoring system in the Los Angeles area and records detailed traffic speed data. The PEMS-BAY, PEMS04, and PEMS08 datasets originate from the California Department of Transportation (Caltrans) Performance Measurement System, with PEMS-BAY recording traffic speed data, while PEMS04 and PEMS08 record traffic flow data.
- Categories:
36 Views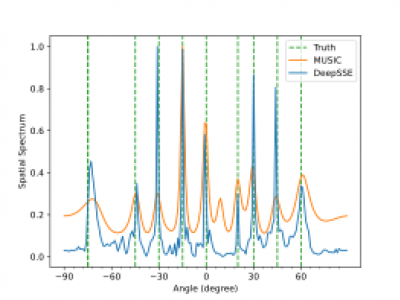
Dataset for multiple signal DOA estmation. This the original dataset used in our research. we consider a ULA with M = 16 antenna elements spaced at half-wavelength distance (l = λ/2). We consider narrowband, non-coherent signals with different intermediate frequencies (IF) transmitted from different sources. The signals are sampled at the intermediate frequency with a sampling frequency of 2.5MHz and 300 sample points. Then we simulate the array received signal according to signal model (1) at different SNRs of {-10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5} dB.
- Categories:
133 Views