Machine Learning

CodePromptEval is a dataset of 7072 prompts designed to evaluate five prompt techniques (few-shot, persona, chain-of-thought, function signature, list of packages) and their effect on the correctness, similarity, and quality of complete functions generated. Each data point in the dataset includes a function generation task, a combination of prompt techniques to be applied, the prompt in natural language that applied the prompt techniques, the ground truth of the functions (human-written functions based on CoderEval dataset by Yu et al.), the tests to evaluate the correctness of the generate
- Categories:
 14 Views
14 Views
Annotated 1,000 misalignment from the SDGSAT-1 glimmer imagery, divided into train, valid, and test sets with a ratio of 7:2:1 for the object detection task.
- Categories:
22 Views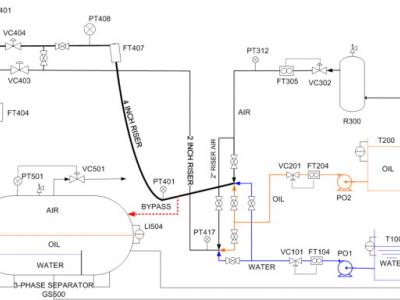
Dateset of the Three-Phase Flow Facility. The Three-phase Flow Facility at Cranfield University is designed to provide a controlled and measured flow rate of water, oil and air to a pressurized system. Fig. 1 shows a simplified sketch of the facility. The test area consists of pipelines with different bore sizes and geometries, and a gas and liquid two-phase separator (0.5 m diameter and 1.2 m high) at the top of a 10.5 m high platform. It can be supplied with single phase of air, water and oil, or a mixture of those fluids, at required rates.
- Categories:
178 Views
The analysis suggests various innovative ideas to improve English instruction, with an emphasis on current technologies and an inclusive approach. These include using AI as a peer tutor, exploring virtual reality to create immersive learning environments, analyzing data to create customized learning materials, integrating local cultural values into instructional materials, implementing a technology-based inclusive learning model, implementing a policy for digital advancement in education, and making the most of contemporary learning resources.
- Categories:
116 Views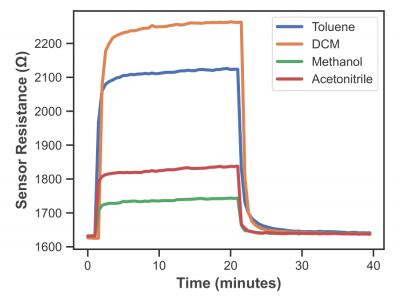
This dataset contains 2,016 sensor responses collected from an array of conductive carbon-black polymer composite sensors, exposed to four target analytes—acetonitrile, dichloromethane (DCM), methanol, and toluene—at nine distinct concentration levels ranging from 0.5% to 20% P/P₀. Each sensor was exposed to the analytes for 20 minutes, followed by 20 minutes of nitrogen flushing to restore the baseline. The data consists of 80 time points (one every 30 seconds) per response, with each time point representing the sensor's resistance to a specific analyte concentration.
- Categories:
32 Views
All the healthcare facilites in this dataset were collected from the MOH 2018 list of Uganda healthcare facilites (https://library.health.go.ug/sites/default/files/resources/National%20Health%20Facility%20MasterLlist%202017.pdf) Additional features were scraped using the Google Maps API and additionally from some of the websites of the healthcare facilities themselves.
- Categories:
49 Views
This paper describes a dataset of droplet images captured using the sessile drop technique, intended for applications in wettability analysis, surface characterization, and machine learning model training. The dataset comprises both original and synthetically augmented images to enhance its diversity and robustness for training machine learning models. The original, non-augmented portion of the dataset consists of 420 images of sessile droplets. To increase the dataset size and variability, an augmentation process was applied, generating 1008 additional images.
- Categories:
113 Views
The Hindi Spam SMS Dataset comprises 3,894 messages, each labeled as either spam or ham. This dataset was meticulously curated with contributions from students who encountered these messages daily. The messages were collected from their experiences and those shared by friends and peers, ensuring a diverse and realistic representation of SMS communication in Hindi. It offers a representative sample of real-world Hindi text messages for analysis. The dataset primarily contains messages written in Hindi, reflecting its origin's linguistic and cultural context.
- Categories:
51 Views
Sarcasm detection involves predicting whether a given text is sarcastic, a challenging task in sentiment analysis. While significant research has been conducted for languages like English, Czech, and Italian, limited work exists for Indian languages such as Hindi, Tamil, and Bengali. Marathi, being the third most spoken language in India, has seen little progress in sarcasm detection, mainly due to the lack of suitable datasets.
- Categories:
27 Views
A dataset of simulated resistive drift series for an illustrative stochastic memristor.
Dataset Description
The memristor has an equilibrium resistance of approximately 500kΩ.
5000 series are generated with starting resistances sampled uniformly from the range [100Ω, 750kΩ].
Each series consists of 1001 datapoints, with the first (zeroth) point corresponding to the initial resistance, and subsequent points sampled at subsequent timesteps.
Dataset Creation
- Categories:
28 Views