Computer Vision

Most existing superpixel algorithms only consider color intensity and position coordinates, while ignoring local neighborhood factors. This limitation leads to low applicability in noisy and cluttered environments. To address this issue, we propose a seminal and novel Fuzzy C-Means clustering with Region Constraints for Superpixel generation (RCFCMS). First, employing region constraints to prevent boundary crossing. Second, adopting spatial information to mitigate noise interference. Third, utilizing soft membership to convert labels.
- Categories:
 18 Views
18 Views
Multi-gait recognition aims to identify persons by their walking styles when walking with other people. A person's gait easily changes a lot when walking with other people. The changes caused by walking with other people are different when walking with different persons, which brings great challenges to high-accuracy multi-gait recognition. Existing multi-gait recognition methods extract hand-crafted multi-gait features. Due to limit of multi-gait sample size and quality, there have not appeared multi-gait recognition methods based on deep learning.
- Categories:
80 Views

The dataset contains the focus metrics values of a comprehensive synthetic underwater image dataset (https://data.mendeley.com/datasets/2mcwfc5dvs/1). The image dataset has 100 ground-truth images and 15,000 synthetic underwater images generated by considering a comprehensive set of effects of underwater environment. The current dataset focus on the focus metrics of these 15,100 images.
- Categories:
165 Views
This is the collection of the Ecuadorian Traffic Officer Detection Dataset. This can be used mainly on Traffic Officer detection projects using YOLO. Dataset is in YOLO format. There are 1862 total images in this dataset fully annotated using Roboflow Labeling tool. Dataset is split as follow, 1734 images for training, 81 images for validation and 47 images for testing. Dataset is annotated only as one class-Traffic Officer (EMOV). The dataset produced a Mean Average Precision(mAP) of 96.4 % using YOLOv3m, 99.0 % using YOLOv5x and 98.10 % using YOLOv8x.
- Categories:
372 Views
The LFW, CASIA FaceV5, and KZDD color datasets are used to validate the clustering ability of MKDCSC for low-quality multi-channel visual data. The LFW and CASIA-FaceV5 datasets are the most widely used public color face datasets in the field of face recognition. They are shot under different lighting conditions and complex backgrounds, and many target objects have varying degrees of data defects.
- Categories:
15 Views
We present the SinOCR and SinFUND datasets, two comprehensive resources designed to advance Optical Character Recognition (OCR) and form understanding for the Sinhala language. SinOCR, the first publicly available and the most extensive dataset for Sinhala OCR to date, includes 100,000 images featuring printed text in 200 different Sinhala fonts and 1,135 images of handwritten text, capturing a wide spectrum of writing styles.
- Categories:
493 Views
This dataset consists of 462 field of views of Giemsa(dye)-stained and field(dye)-stained thin blood smear images acquired using an iPhone 10 mobile phone with a 12MP camera. The phone was attached to an Olympus microscope with 1000× objective lens. Half of the acquired images are red blood cells with a normal morphology and the other half have a Rouleaux formation morphology.
- Categories:
955 Views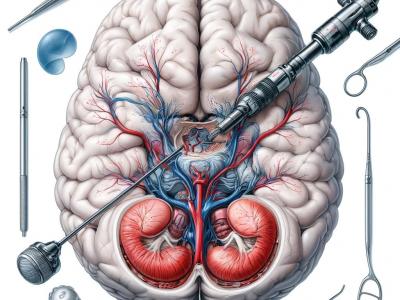
This dataset comprises 1718 annotated images extracted from 29 video clips recorded during Endoscopic Third Ventriculostomy (ETV) procedures, each captured at a frame rate of 25 FPS. Out of these images, 1645 are allocated for the training set, while the remainder is designated for the testing set. The images contain a total of 4013 anatomical or intracranial structures, annotated with bounding boxes and class names for each structure. Additionally, there are at least three language descriptions of varying technicality levels provided for each structure.
- Categories:
410 Views
This is the first multi-view, semi-indoor gait dataset captured with the DAVIS346 event camera. The dataset comprises 6,150 sequences, capturing 41 subjects from five different view angles under two lighting conditions. Specifically, for each lighting condition and view angle, there are six sequences representing normal walking (NM), three sequences representing walking with a backpack (BG), three sequences representing walking with a portable bag (PT), and three sequences representing walking while wearing a coat (CL).
- Categories:
96 Views