Computer Vision

PRECIS HAR represents a RGB-D dataset for human activity recognition, captured with the 3D camera Orbbec Astra Pro. It consists of 16 different activities (stand up, sit down, sit still, read, write, cheer up, walk, throw paper, drink from a bottle, drink from a mug, move hands in front of the body, move hands close to the body, raise one hand up, raise one leg up, fall from bed, and faint), performed by 50 subjects.
- Categories:
 3213 Views
3213 Views
The dataset consists of 60285 character image files which has been randomly divided into 54239 (90%) images as training set 6046 (10%) images as test set. The collection of data samples was carried out in two phases. The first phase consists of distributing a tabular form and asking people to write the characters five times each. Filled-in forms were collected from around 200 different individuals in the age group 12-23 years. The second phase was the collection of handwritten sheets such as answer sheets and classroom notes from students in the same age group.
- Categories:
671 Views
Water meter dataset. Contains 1244 water meter images. Assembled using a crowdsourcing platform Yandex.Toloka.
- Categories:
4301 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed. To achieve this goal, we introduced a large-sacle (1.M images) object recognition dataset (CURE-OR) which is among the most comprehensive datasets with controlled synthetic challenging conditions. In CURE
- Categories:
1892 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed. To achieve this goal, we introduced a large-sacle (~1.72M frames) traffic sign detection video dataset (CURE-TSD) which is among the most comprehensive datasets with controlled synthetic challenging conditions. The video sequences in the
- Categories:
5224 Views
The dataset was built by capturing the static gestures of the American Sign Language (ASL) alphabet, from 8 people, except for the letters J and Z, since they are dynamic gestures. To capture the images, we used a Logitech Brio webcam, with a resolution of 1920 × 1080 pixels, in a university laboratory with artificial lighting. By extracting only the hand region, we defined an area of 400 × 400 pixels for the final image of our dataset.
- Categories:
6556 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on the robustness of data-driven algorithms under diverse challenging conditions where trained models can possibly be depolyed.
- Categories:
4063 Views
The Dataset
The Onera Satellite Change Detection dataset addresses the issue of detecting changes between satellite images from different dates.
- Categories:
31295 Views
Pedestrian detection and lane guidance
- Categories:
368 Views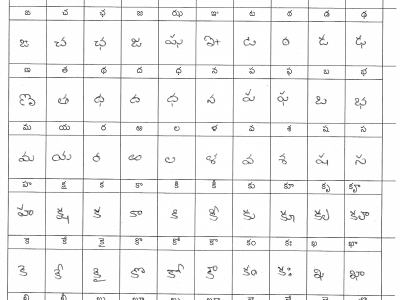
This dataset contains sheets of handwritten Telugu characters separated in boxes. It contains vowel, consonant, vowel-consonant and consonant-consonant pairs of Telugu characters. The purpose of this dataset is to act as a benchmark for Telugu handwritting related tasks like character recognition. There are 11 sheet layouts that produce 937 unique Telugu characters. Eighty three writers participated in generating the dataset and contributed 913 sheets in all. Each sheet layout contains 90 characters except the last which contains 83 characters where the last 10 are english numerals 0-9.
- Categories:
1710 Views