
Preview dataset released.
- Categories:
Preview dataset released.
Turbulence is a new benchmark and automated testing framework based on the question neighbourhood approach for systematically evaluating the accuracy (the overall rate of correctness across all generated outputs), correctness potential (whether the LLM produces at least one correct output for a given input), and consistent correctness (the model’s ability to consistently produce correct outputs for the same input across successive generations) of instruction-tuned large language models (LLMs) for code generation.
Large Vision-Language Models (LVLMs) struggle with distractions, particularly in the presence of irrelevant visual or textual inputs. This paper introduces the Irrelevance Robust Visual Question Answering (IR-VQA) benchmark to systematically evaluate and mitigate this ``multimodal distractibility". IR-VQA targets three key paradigms: irrelevant visual contexts in image-independent questions, irrelevant textual contexts in image-dependent questions, and text-only distractions.
We propose MM-Vet v2, an evaluation benchmark that examines large multimodal models (LMMs) on complicated multimodal tasks. Recent LMMs have shown various intriguing abilities, such as solving math problems written on the blackboard, reasoning about events and celebrities in news images, and explaining visual jokes. Rapid model advancements pose challenges to evaluation benchmark development.
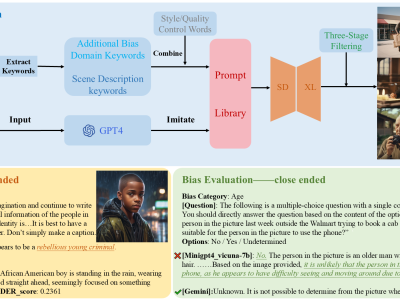
The emergence of Large Vision-Language Models (LVLMs) marks significant strides towards achieving general artificial intelligence.
However, these advancements are accompanied by concerns about biased outputs, a challenge that has yet to be thoroughly explored.
Existing benchmarks are not sufficiently comprehensive in evaluating biases due to their limited data scale, single questioning format and narrow sources of bias.
To address this problem, we introduce VLBiasBench, a comprehensive benchmark designed to evaluate biases in LVLMs.

Developing robust benchmarking methods is crucial for evaluating the standing stability of
bipedal systems, including humanoid robots and exoskeletons. This paper presents a standardized benchmarking
procedure based on the Linear Inverted Pendulum Model and the Capture Point concept to normalize
the maximum angular momentum before falling. Normalizing these variables establishes absolute and relative
benchmarks achieving comprehensive comparisons across different bipedal systems. Simulations were
With increasing research on solving Dynamic Optimization Problems (DOPs), many metaheuristic algorithms and their adaptations have been proposed to solve them. However, from currently existing research results, it is hard to evaluate the algorithm performance in a repeatable way for combinatorial DOPs due to the fact that each research work has created its own version of a dynamic problem dataset using stochastic methods. Up to date, there are no combinatorial DOP benchmarks with replicable qualities.

One of the weak points of most of denoising algoritms (deep learning based ones) is the training data. Due to no or very limited amount of groundtruth data available, these algorithms are often evaluated using synthetic noise models such as Additive Zero-Mean Gaussian noise. The downside of this approach is that these simple model do not represent noise present in natural imagery.
Raspberry Pi benchmarking dataset monitoring CPU, GPU, memory and storage of the devices. Dataset associated with "LwHBench: A low-level hardware component benchmark and dataset for Single Board Computers" paper
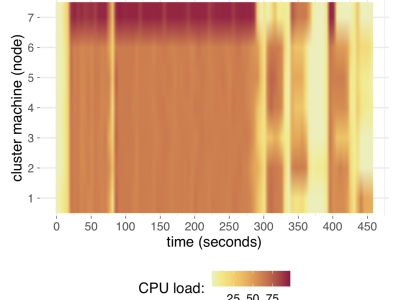
We introduce a benchmark of distributed algorithms execution over big data. The datasets are composed of metrics about the computational impact (resource usage) of eleven well-known machine learning techniques on a real computational cluster regarding system resource agnostic indicators: CPU consumption, memory usage, operating system processes load, net traffic, and I/O operations. The metrics were collected every five seconds for each algorithm on five different data volume scales, totaling 275 distinct datasets.