BCI

We developed a unique and valuable dataset specifically for advancing Brain-Computer Interface (BCI) systems by recording brain activity from a dedicated volunteer. The participant was asked to pronounce 100 carefully selected Malayalam words, along with their English translations, which were chosen for their relevance to astronauts during human space missions. The volunteer pronounced these words both vocally and subvocally, each word being repeated 50 times. Non-invasive Electroencephalography (EEG) sensors were employed to capture the brain activity associated with these tasks.
- Categories:
 721 Views
721 Views
In today’s context, it is essential to develop technologies to help older patients with neurocognitive disorders communicate better with their caregivers. Research in Brain Computer Interface, especially in thought-to-text translation has been carried out in several languages like Chinese, Japanese and others. However, research of this nature has been hindered in India due to scarcity of datasets in vernacular languages, including Malayalam. Malayalam is a South Indian language, spoken primarily in the state of Kerala by bout 34 million people.
- Categories:
936 Views
This article provides an introduction to the field of datasets, including their types, characteristics, and applications. Datasets refer to collections of data that have been organized for specific purposes. They can come in various forms, including structured data, unstructured data, and semi-structured data. Each type of dataset has its own unique characteristics and uses. For example, structured data typically includes datasets that have been organized into tables and rows, such as spreadsheets or databases, while unstructured data typically includes text, images, and videos.
- Categories:
349 Views
Brain-Computer Interface (BCI) has become an established technology to interconnect a human brain and an external device. One of the most popular protocols for BCI is based on the extraction of the so-called P300 wave from EEG recordings. P300 wave is an event-related potential with a latency of 300 ms after the onset of a rare stimulus. In this paper, we used deep learning architectures, namely convolutional neural networks (CNNs), to improve P300-based BCIs.
- Categories:
1028 Views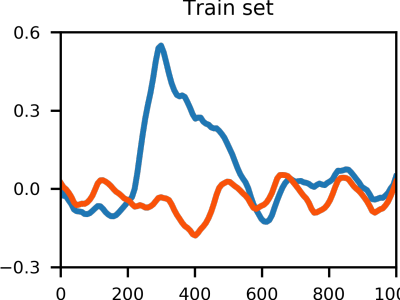
Dataset description
This dataset contains EEG signals from 73 subjects (42 healthy; 31 disabled) using an ERP-based speller to control different brain-computer interface (BCI) applications. The demographics of the dataset can be found in info.txt. Additionally, you will find the results of the original study broken down by subject, the code to build the deep-learning models used in [1] (i.e., EEG-Inception, EEGNet, DeepConvNet, CNN-BLSTM) and a script to load the dataset.
Original article:
- Categories:
3141 Views
One subject, five different movements, four levels of motor imagery data.The sampling rate is 25Hz, a total of 33,000 lines.
- Categories:
482 Views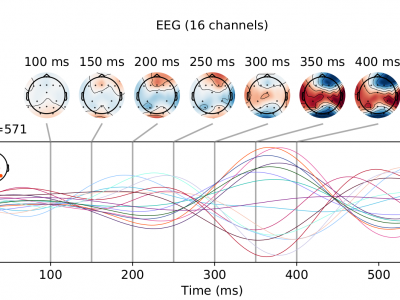
The EEG data were acquired from 16 healthy young adults (age range 22 - 30 years) with no neurological, physical, or psychiatric illness history. All the participants were naive BCI users who had not participated in any related experiments before. Informed consent was received from all participants.
- Categories:
5639 Views
Mobile Brain-Body Imaging (MoBI) technology was deployed at the Museo de Arte Contemporáneo (MARCO) in Monterrey, México, in an effort to collect Electroencefalographic (EEG) data from large numbers (N = ~1200) of participants and allow the study of the brain’s response to artistic stimuli, as part of the studies developed by University of Houston (TX, USA) and Tecnológico de Monterrey (MTY, México).
- Categories:
475 Views