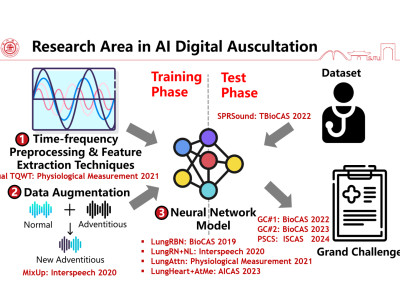
It has proved that the auscultation of respiratory sound has advantage in early respiratory diagnosis. Various methods have been raised to perform automatic respiratory sound analysis to reduce subjective diagnosis and physicians’ workload. However, these methods highly rely on the quality of respiratory sound database. In this work, we have developed the first open-access paediatric respiratory sound database, SPRSound. The database consists of 2,683 records and 9,089 respiratory sound events from 292 participants.
- Categories:

