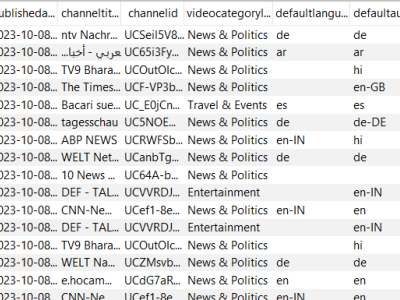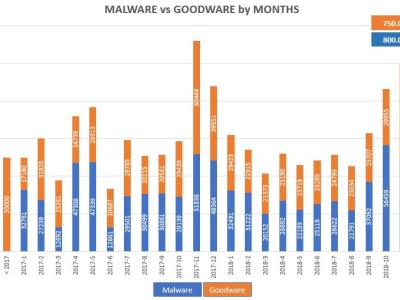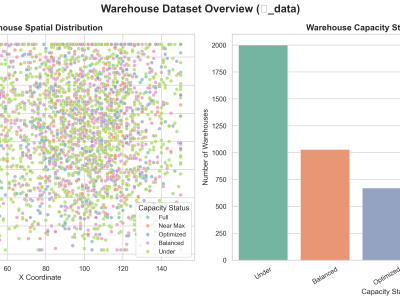
This dataset, denoted as 𝑾_data, represents a synthetic yet structurally authentic warehouse management dataset comprising 4,132 records and 11 well-defined attributes. It was generated using the Gretel.ai platform, following the structural standards provided by the TI Supply Chain API–Storage Locations specification. The dataset encapsulates essential operational and spatial parameters of warehouses, including unique identifiers, geospatial coordinates, storage capacities, and categorical capacity statuses.
- Categories: