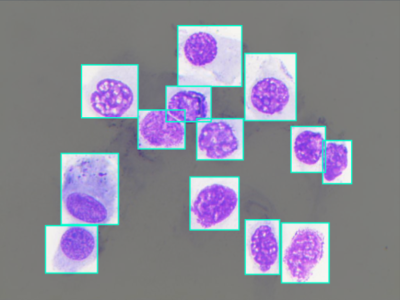
Along with the continuous growth of Internet usage, mobile users are becoming increasingly relevant as they are responsible for the largest percentage of web traffic. Conse- quently, a large and growing body of literature has been based on cellular data to gain a deeper understanding of several Internet-related concerns. Nevertheless, accessing high-quality cellular datasets can be a challenge for research teams due to scarcity and restricted access.
- Categories: