Other

This study was conducted with the aim of determining the ability of MSME actors to understand, use, and evaluate information obtained through digital media. This study examines in more depth the impact of digital literacy in forming cognitive and technical skills to communicate and interact effectively with consumers. This study uses a descriptive qualitative approach method by conducting in-depth interviews with 11 informants including one key informant, namely the Chairperson of the MSME Association in Kotamobagu.
- Categories:
 18 Views
18 Views
This dataset provides a GraphML‐based representation of an interdependent infrastructure system, covering power, water, transportation, and community infrastructures. Each node is annotated with key attributes such as resource type, criticality, societal vulnerability score (SVS), and capacity—while directed edges capture the flow or dependency relationships among these resources. The dataset facilitates resilience and recovery analysis by enabling repair order simulation, based on certain metrics‐based prioritization.
- Categories:
30 Views
In China’s evolving FinTech ecosystem, intelligent recommendation systems have become pivotal for enhancing crowdfunding outcomes. This study integrates the Information Systems Success Model, Dynamic Capabilities Theory, Signaling Theory, and Trust Theory to examine how such systems shape crowdfunding success. Adopting a positivist and quantitative approach, data were collected from 302 users of Chinese crowdfunding platforms employing intelligent recommendation engines.
- Categories:
30 Views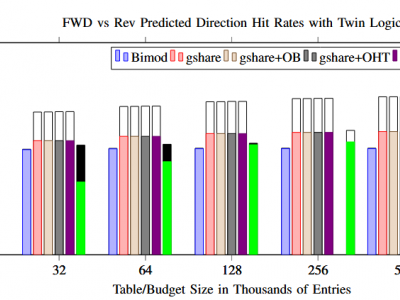
Contains data supporting the IEEE TC submission titled "General Principles for Implementing Branch Prediction in Fully Adiabatic, Reversible, and SuperScalar (FARS) Processors". Paper abstract: Adiabatic and reversible logic families take advantage of Landauer's principle to provide a more efficient means of computation using conventional MOSFETs. However, there are performance drawbacks inherent in the way such devices physically operate. Such drawbacks can be overcome by scaling the number of devices to meet performance needs.
- Categories:
69 Views
In this dataset, the simulation files of some examples present in the paper "The Power-Oriented Graphs Modeling Technique: From the Fundamental Principles to the Systematic, Step-By-Step Modeling of Complex Physical Systems" are reported. The examples include an electrical system, an hydraulic system, and a DC motor driving an hydraulic pump. The files include ready-to-run Matlab/Simulink simulation files of the system and a report containing the model and and simulation results.
- Categories:
26 Views
The dataset used in this study is sourced from benchmark datasets~\cite{marcelli2022machine} for binary similarity detection and was decompiled using \textit{IDA Pro 7.5}. We selected the following datasets for evaluation: \textit{Coreutils-ARM-32}, \textit{Curl-MIPS-32}, \textit{ImageMagick-ARM-32}, \textit{OpenSSL-X86-32}, \textit{Putty-X86-32}, and \textit{SQLite-X86-32}. These datasets are commonly used, but their application scenarios are relatively limited.
- Categories:
14 Views
This dataset was produced as part of the NANCY project (https://nancy-project.eu/), with the aim of using it in the fields of communication and
- Categories:
287 Views
Architected materials, which are designed and engineered with specific microstructures, hold great promise for healthcare applications. In particular, tensile samples based on architected materials exhibit unique properties that can address key challenges in medical devices and implants. By precisely controlling the architecture at the micro- and nano-scale, these materials can be optimized for high strength-to-weight ratio, tunable stiffness, and enhanced biocompatibility.
- Categories:
173 Views
This dataset contains detailed player end-game statistics (e.g., number of kills) and in-game events (e.g., player kills) from all professional League of Legends matches held between September 15, 2019, and September 15, 2024. It encompasses a total of 37,388 matches across 392 tournaments, featuring 4,927 unique players. Matches come from all regions and tiers of play.
- Categories:
753 Views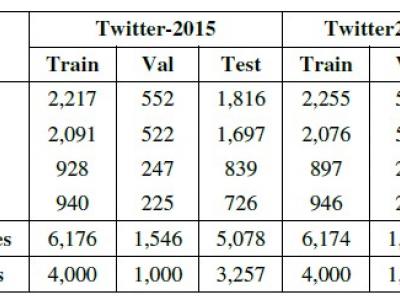
<p>The <strong>Twitter2015-Urdu Dataset</strong> is a multimodal resource designed to advance Multimodal Named Entity Recognition (MNER) research in Urdu, a low-resource language. It adapts the widely used Twitter2015 English dataset with culturally grounded annotations tailored to Urdu's unique linguistic complexities.
- Categories:
25 Views