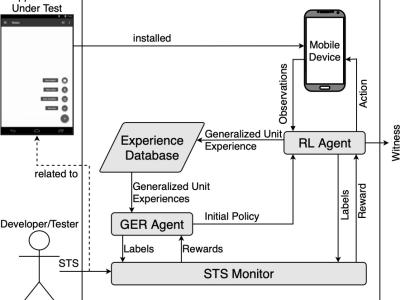
This work aims to identify anomalous patterns that could be associated with performance degradation and failures in datacenter nodes, such as Virtual Machines or Virtual Machines clusters. The early detection of anomalies can enable early remediation measures, such as Virtual Machines migration and resource reallocation before losses occur. One way to detect anomalous patterns in datacenter nodes is using monitoring data from the nodes, such as CPU and memory utilization.
- Categories: