Artificial Intelligence

Mapping millions of buried landmines rapidly and removing them cost-effectively is supremely important to avoid their potential risks and ease this labour-intensive task. Deploying uninhabited vehicles equipped with multiple remote sensing modalities seems to be an ideal option for performing this task in a non-invasive fashion. This report provides researchers with vision-based remote sensing imagery datasets obtained from a real landmine field in Croatia that incorporated an autonomous uninhabited aerial vehicle (UAV), the so-called LMUAV.
- Categories:
 1156 Views
1156 Views
Gowers' Sign is a visual symptom exhibited by many neuromuscular dystrophies, including Becker muscular dystrophy, congenital muscular dystrophy, congenital myopathy, and Duchenne muscular dystrophy, which is the most aggressive, with a life expectancy of 20 to 30 years. Additionally, there is a 2.5-year gap between the onset of initial symptoms and a confirmed diagnosis. Early detection allows for the treatment of the disease, leading to a better quality of life. To the best of our knowledge, a non-invasive computer vision system for detecting Gowers' Sign has not yet been proposed.
- Categories:
19 Views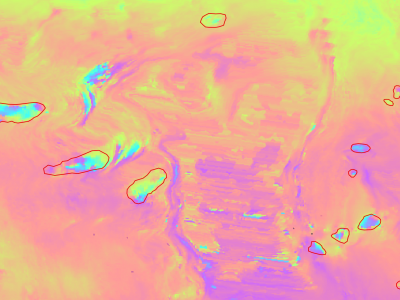
Slow moving motions are mostly tackled by using the phase information of Synthetic Aperture Radar (SAR) images through Interferometric SAR (InSAR) approaches based on machine and deep learning. Nevertheless, to the best of our knowledge, there is no dataset adapted to machine learning approaches and targeting slow ground motion detections. With this dataset, we propose a new InSAR dataset for Slow SLIding areas DEtections (ISSLIDE) with machine learning. The dataset is composed of standardly processed interferograms and manual annotations created following geomorphologist strategies.
- Categories:
901 Views
The "ShrimpView: A Versatile Dataset for Shrimp Detection and Recognition" is a meticulously curated collection of 10,000 samples (each with 11 attributes) designed to facilitate the training of deep learning models for shrimp detection and classification. Each sample in this dataset is associated with an image and accompanied by 11 categorical attributes.
- Categories:
1095 Views
The constructed Aoralscan3 tooth registration dataset includes 1667 samples for training, 156 samples for validation, and 176 samples for testing. Jaw models are generated from hospital patients by oral scanning. The ground truth of the relative pose of each tooth is generated by adding random jittering to the tooth models. For each tooth, ground truth relative pose information was generated by introducing random jittering to the tooth models. This dataset can be used for point cloud registration.
- Categories:
95 Views
The training set, validation set, and testing set in the constructed Shining3D tooth pose dataset contain 1689, 150, and 150 samples, respectively. Jaw models are generated from hospital patients by oral scanning. The ground truth of the relative pose of each tooth is generated by adding random jittering to the tooth models. For each tooth, ground truth relative pose information was generated by introducing random jittering to the tooth models.
- Categories:
147 Views
The Aoralscan3 dataset includes 1573, 244, and 244 videos for the corresponding sets. The uniform size of the images in the dataset is 640 × 480 pixels. LabelMe software is employed to accurately mark the boundary and classify the region of each tooth in the datasets. This dataset is usef for orthodontic treatment. which is one of the research direction of artificial intelligence using current images and previous 3D models to estimate the relative position of individual teeth before and after orthodontic treatment.
- Categories:
348 Views
This is a PART of the dataset used in our paper titled "Detecting Anomalous Robot Motion in Collaborative Robotic Manufacturing Systems".
- Categories:
31 Views
This is a PART of the dataset used in our paper titled "Detecting Anomalous Robot Motion in Collaborative Robotic Manufacturing Systems".
- Categories:
36 Views
The Shining3D dataset consists of 1866, 272, and 272 videos for the training, validation, and testing sets, respectively. The uniform size of the images in the dataset is 640 × 480 pixels. LabelMe software is employed to accurately mark the boundary and classify the region of each tooth in the datasets. This dataset is usef for orthodontic treatment. Orthodontic treatment monitoring, one of the research direction of artificial intelligence, involves using current images and previous 3D models to estimate the relative position of individual teeth before and after orthodontic treatment.
- Categories:
558 Views