Artificial Intelligence

Since the majority of people have smartphones, the Hb level can be determined using the smartphone's video through PPG signal as opposed to the traditional approaches, which still require the use of a needle to puncture a vein. This study enrolled 108 subjects who underwent a clinical test, with their hemoglobin (Hb) level within the range of 6.6 to 16.5 g/dL.
- Categories:
 191 Views
191 Views
Since the majority of people have smartphones, the Hb level can be determined using the smartphone's video through PPG signal as opposed to the traditional approaches, which still require the use of a needle to puncture a vein. This study enrolled 108 subjects who underwent a clinical test, with their hemoglobin (Hb) level within the range of 6.6 to 16.5 g/dL.
- Categories:
43 Views
Path information in knowledge graphs can provide explicit explanations for recommendation decisions, thus becoming a focus in explainable recommendation research.Path information in knowledge graphs can provide explicit explanations for recommendation decisions, thus becoming a focus in explainable recommendation research.Path information in knowledge graphs can provide explicit explanations for recommendation decisions, thus becoming a focus in explainable recommendation research.Path information in knowledge graphs can provide explicit explanations for recommendation decisions, thus becom
- Categories:
15 Views
Dual-polarization (dual-pol) radar can measure additional parameters that provide more microphysical information of precipitation systems than those provided by conventional Doppler radar. The dual-pol parameters have been successfully utilized to investigate precipitation microphysics and improve radar quantitative precipitation estimation (QPE). The recent progress in dual-pol radar research and applications in China is summarized in four aspects. Firstly, the characteristics of several representative dual-pol radars are reviewed.
- Categories:
112 Views
Our released weight dataset for fusion results in edge-cloud collaborative inference contains the corresponding weighted summation weights under 50,000 edge-cloud collaborative DNN inference tasks, listing the five heterogeneous NVIDIA edge devices they use (NVIDIA Jetson Nano, TX2, NX, Orin NX, and AGX Orin), computing power (1.9~275TOPS), DNN model type (EfficientNet-B0, ViT-B16), and network bandwidth (0.5~8Mbps).
- Categories:
277 Views
The MalariaSD dataset encompasses diverse stages and classes of malaria parasites, including Plasmodium falciparum, Plasmodium malariae, Plasmodium vivax, and Plasmodium ovale, categorized into four phases: ring, schizont, trophozoite, and gametocyte.
- Categories:
1115 Views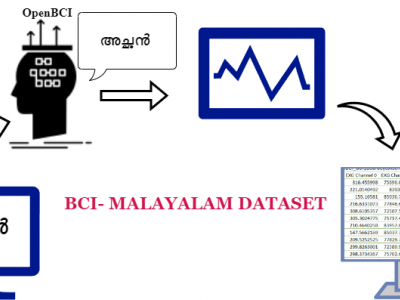
In today’s context, it is essential to develop technologies to help older patients with neurocognitive disorders communicate better with their caregivers. Research in Brain Computer Interface, especially in thought-to-text translation has been carried out in several languages like Chinese, Japanese and others. However, research of this nature has been hindered in India due to scarcity of datasets in vernacular languages, including Malayalam. Malayalam is a South Indian language, spoken primarily in the state of Kerala by bout 34 million people.
- Categories:
851 Views
The Deepfake face detection task involves a facial image of unknown authenticity for testing. While most deepfake detection methods take only the image as input, our literature demonstrates that conditioning the deepfake detector on identity—i.e., knowing whose deepfake face the picture might be—can enhance detection performance. Existing deepfake detection datasets, such as FaceForensics++ and DFDC, do not include identity information for authentic and deepfake faces.
- Categories:
2543 Views
The presented dataset encompasses a diverse collection of road images captured under a multitude of environmental conditions, specifically sourced from Tunisian highways. Comprising textual annotations in two languages, this dataset is tailored to facilitate research and development in the domain of scene understanding, language processing, and bilingual context analysis. The collection includes 2006 word pictures with Latin and Arabic text occurrences that were taken from 3000 road scene images. The dataset's versatility enables investigations into the robustness of lang
- Categories:
117 Views
The presented dataset encompasses a diverse collection of road images captured under a multitude of environmental conditions, specifically sourced from Tunisian highways. Comprising textual annotations in two languages, this dataset is tailored to facilitate research and development in the domain of scene understanding, language processing, and bilingual context analysis. The collection includes 2006 word pictures with Latin and Arabic text occurrences that were taken from 3000 road scene images. The dataset's versatility enables investigations into the robustness of lang
- Categories:
36 Views