Artificial Intelligence

TDC560 dataset contains 560 difficult images, one of which are selected from the testing set of CTW1500 and TD500, others are generated by ourselves with text-line annotations. In the selecting process, we sort images with the extreme spatial distances between characters and words.
- Categories:
 56 Views
56 Views
The unfolding of the COVID-19 outbreak was an unprecedented and unanticipated opportunity to understand how a sudden global shock modulates people’s online searches when seeking information about their emotional well-being. Furthermore, it also illustrated how public health surveillance systems were essential for tracking diseases’ spatial and temporal dynamics and shaping rapid public policy changes.
- Categories:
305 Views
SHORT DESCRIPTION: The dataset was obtained as a result of the extinguishing tests of four different fuel flames with a sound wave extinguishing system. The sound wave fire-extinguishing system consists of 4 subwoofers with a total power of 4,000 Watt placed in the collimator cabinet. There are two amplifiers that enable the sound come to these subwoofers as boosted. Power supply that powers the system and filter circuit ensuring that the sound frequencies are properly transmitted to the system is located within the control unit.
- Categories:
920 Views
Artificial database that simulates COVID-19 patients and critical situations to be able to evaluate the BeCalm system performance (https://www.idatis.org/proyecto-becalm/). Generated with https://github.com/BOSCH-UCM/BeCalm
- Categories:
368 Views
Raspberry Pi benchmarking dataset monitoring CPU, GPU, memory and storage of the devices. Dataset associated with "LwHBench: A low-level hardware component benchmark and dataset for Single Board Computers" paper
- Categories:
280 Views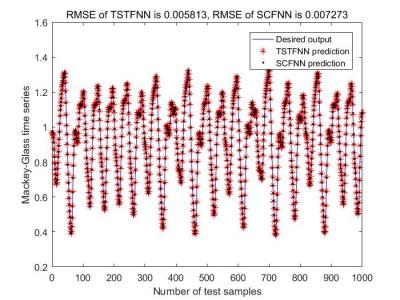
Prediction results of TSTFNN and SCFNN for Mackey-Glass time series
- Categories:
375 Views
The C3I Thermal Automotive Dataset provides > 35,000 distinct frames along with annotated thermal frames for the development of smart thermal perception system/ object detection system that will enable the automotive industry and researchers to develop safer and more efficient ADAS and self-driving car systems. The overall dataset is acquired, processed, and open-sourced in challenging weather and environmental scenarios. The dataset is recorded from a lost-cost yet effective 640x480 uncooled LWIR thermal camera.
- Categories:
2796 Views
Some abstract.
- Categories:
15 Views
The lack of quality label data is considered one of the main bottlenecks for training machine and deep learning models. Weakly supervised learning using incomplete, coarse, or inaccurate data is an alternative strategy to overcome the scarcity of training data. We trained a U-Net model for segmenting Buildings’ footprints from a high-resolution digital elevation model, using existing label data from the open-access Microsoft building footprints data set.
- Categories:
233 Views
This dataset contains survey results collected from new recommendation system. This dataset asks about how the people accept recommendation systems from the AI trustworthiness and recommendation quality aspect.
- Categories:
303 Views