Machine Learning

# Datasets for stage 3
The datasets were collected from a software-based simulation environment simulating a small-scale IEC 61850-compliant substation with both the primary plant and the process bus.
The datasets consist of 148 attack scenarios, each scenario includes two benign behaviours (fault-free behaviours and emergency behaviours) and one type of malicious behaviour.
- Categories:
 91 Views
91 Views
Accurate prediction of protein-ligand binding affinities (PLAs) is essential for drug discovery, repositioning, and design.
- Categories:
35 Views
Captcha stands for Completely Automated Public Turing Tests to Distinguish Between Humans and Computers. This test cannot be successfully completed by current computer systems; only humans can. It is applied in several contexts for machine and human identification. The most common kind found on websites are text-based CAPTCHAs.A CAPTCHA is made up of a series of alphabets or numbers that are linked together in a certain order.
- Categories:
342 Views
In medical applications, machine learning often grapples with limited training data. Classical self-supervised deep learning techniques have been helpful in this domain, but these algorithms have yet to achieve the required accuracy for medical use. Recently quantum algorithms show promise in handling complex patterns with small datasets. To address this challenge, this study presents a novel solution that combines self-supervised learning with Variational Quantum Classifiers (VQC) and utilizes Principal Component Analysis (PCA) as the dimensionality reduction technique.
- Categories:
117 Views
The dataset encompasses an extensive collection of patient information, delving into their comprehensive medical background, encompassing a myriad of features that encapsulate not only the physical but also the mental and emotional states. Furthermore, the dataset is enriched with invaluable ECG data derived from the patients. Moreover, our dataset boasts additional features meticulously extracted from the ECG records, thereby enhancing the potential for our machine learning model to undergo more effective training with our rich and diverse data.
- Categories:
589 Views
The choice of the dataset is the key for OCR systems. Unfortunately, there are very few works on Telugu character datasets. The work by Pramod et al has 500 words and an average of 50 images with 50 fonts in four styles for training data each image of size 48x48 per category. They used the most frequently occurring words in Telugu but were unable to cover all the words in Telugu. Later works were based on character level. The dataset by Hastie has 460 classes and 160 samples per class which is made up of 500 images.
- Categories:
638 Views
Distribution and power transformers are essential components of any electricity network, hence electrical and mechanical safety of the transformer unit is among the highest concerns of electricity providers. Over the course of their operation, transformers face with a wide range of internal and external disturbances which may lead to a partial or full malfunction of the equipment. The service life and condition requirements for distribution and power transformers are now changed and utilities altered their maintenance policy from time-based to condition-based approach.
- Categories:
93 Views
We define personal risk detection as the timely identification of when someone is in the midst of a dangerous situation, for example, a health crisis or a car accident, events that may jeopardize a person’s physical integrity. We work under the hypothesis that a risk-prone situation produces sudden and significant deviations in standard physiological and behavioural user patterns. These changes can be captured by a group of sensors, such as the accelerometer, gyroscope, and heart rate.
- Categories:
771 Views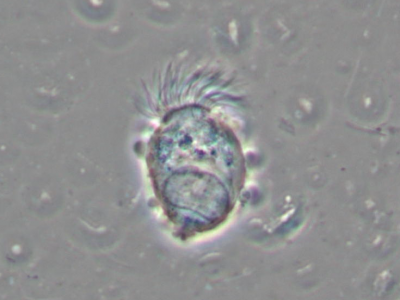
Nasal cytology is a medicine field that focuses on the examination of nasal mucosa cells with the objective of recognizing changes in the epithelium, which is frequently subjected to acute or chronic irritation and inflammation caused by viruses, bacteria, or fungi; in the last decade, nasal cytology is becoming increasingly critical in diagnosing nasal conditions.
- Categories:
245 Views
The Internet Graphs (IGraphs) dataset is a substantial collection of real intra-AS (Autonomous System) graphs sourced from the Internet Topology Data Kit (ITDK) project. Comprising a total of 90,326 graphs, each ranging from 12 to 250 nodes, this dataset provides a diverse and extensive resource for the exploration and analysis of network structures within autonomous systems.
- Categories:
842 Views