Machine Learning
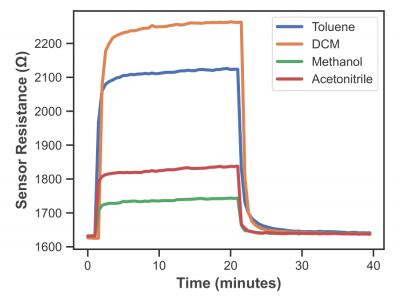
This dataset contains 2,016 sensor responses collected from an array of conductive carbon-black polymer composite sensors, exposed to four target analytes—acetonitrile, dichloromethane (DCM), methanol, and toluene—at nine distinct concentration levels ranging from 0.5% to 20% P/P₀. Each sensor was exposed to the analytes for 20 minutes, followed by 20 minutes of nitrogen flushing to restore the baseline. The data consists of 80 time points (one every 30 seconds) per response, with each time point representing the sensor's resistance to a specific analyte concentration.
- Categories:
 90 Views
90 Views
All the healthcare facilites in this dataset were collected from the MOH 2018 list of Uganda healthcare facilites (https://library.health.go.ug/sites/default/files/resources/National%20Health%20Facility%20MasterLlist%202017.pdf) Additional features were scraped using the Google Maps API and additionally from some of the websites of the healthcare facilities themselves.
- Categories:
69 Views
This paper describes a dataset of droplet images captured using the sessile drop technique, intended for applications in wettability analysis, surface characterization, and machine learning model training. The dataset comprises both original and synthetically augmented images to enhance its diversity and robustness for training machine learning models. The original, non-augmented portion of the dataset consists of 420 images of sessile droplets. To increase the dataset size and variability, an augmentation process was applied, generating 1008 additional images.
- Categories:
161 Views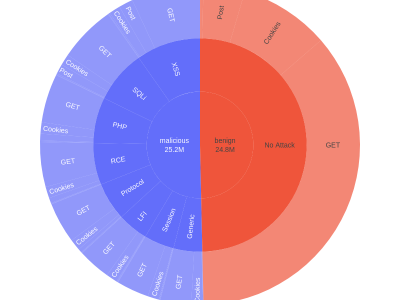
Validating defenses to meet emerging cybersecurity challenges requires continuous updates to the datasets used for testing. In this paper, we introduce the Firewall Attack Detection Extractions (FADE) dataset designed to address gaps in available collections by generating a diverse and balanced corpus of over 10 million categorized attacks derived from open-source rule sets and public penetration testing repositories.
- Categories:
74 Views
The Hindi Spam SMS Dataset comprises 3,894 messages, each labeled as either spam or ham. This dataset was meticulously curated with contributions from students who encountered these messages daily. The messages were collected from their experiences and those shared by friends and peers, ensuring a diverse and realistic representation of SMS communication in Hindi. It offers a representative sample of real-world Hindi text messages for analysis. The dataset primarily contains messages written in Hindi, reflecting its origin's linguistic and cultural context.
- Categories:
110 Views
Sarcasm detection involves predicting whether a given text is sarcastic, a challenging task in sentiment analysis. While significant research has been conducted for languages like English, Czech, and Italian, limited work exists for Indian languages such as Hindi, Tamil, and Bengali. Marathi, being the third most spoken language in India, has seen little progress in sarcasm detection, mainly due to the lack of suitable datasets.
- Categories:
49 Views
A dataset of simulated resistive drift series for an illustrative stochastic memristor.
Dataset Description
The memristor has an equilibrium resistance of approximately 500kΩ.
5000 series are generated with starting resistances sampled uniformly from the range [100Ω, 750kΩ].
Each series consists of 1001 datapoints, with the first (zeroth) point corresponding to the initial resistance, and subsequent points sampled at subsequent timesteps.
Dataset Creation
- Categories:
34 Views
PPE Usage Dataset
This repository provides the Personal Protective Equipment (PPE) Usage Dataset, designed for training deep neural networks (DNNs). The dataset was collected using the EFR32MG24 microcontroller and the ICM-20689 inertial measurement unit, which features a 3-axis gyroscope and a 3-axis accelerometer.
The dataset includes data for four types of PPE: helmet, shirt, pants, and boots, categorized into three activity classes: carrying, still, and wearing.
- Categories:
67 Views
The 5G cellular technology has introduced advanced radio communication protocols and new frequency bands and enabled faster data exchange. These improvements increase network capacity and establish a foundation for high-bandwidth, low-latency services, helping the development of applications like the Internet of Things (IoT). However, information security poses significant challenges, particularly concerning attacks such as Fake Base Stations (FBS) and Stream Control Transmission Protocol (SCTP) Session Hijacking.
- Categories:
356 Views
The benchmarking dataset, GenAI on the Edge, contains performance metrics from evaluating Large Language Models (LLMs) on edge devices, utilizing a distributed testbed of Raspberry Pi devices orchestrated by Kubernetes (K3s). It includes performance data collected from multiple runs of prompt-based evaluations with various LLMs, leveraging Prometheus and the Llama.cpp framework. The dataset captures key metrics such as resource utilization, token generation rates/throughput, and detailed inference timing for stages such as Sample, Prefill, and Decode.
- Categories:
379 Views