Computer Vision

Nankai Chinese Font Style dataset contains both handwriting and standard printing. Furthermore, the Chinese characters in each font style include not only the fifirst-level simplifified Chinese characters,but also some rare characters and ancient Chinese charactersthat cannot be represented by Unicode encoding.
- Categories:
 147 Views
147 Views
We present below a sample dataset collected using our framework for synthetic data collection that is efficient in terms of time taken to collect and annotate data, and which makes use of free and open source software tools and 3D assets. Our approach provides a large number of systematic variations in synthetic image generation parameters. The approach is highly effective, resulting in a deep learning model with a top-1 accuracy of 72% on the ObjectNet data, which is a new state-of-the-art result.
- Categories:
625 Views
This is the supplemental material to the paper "fast computation of neck-like features".
- Categories:
36 Views
The MPSC-rPPG dataset comprises photoplethysmograph (rPPG) data with the PPG ground truth, making it a perfect dataset to evaluate various algorithms for extracting PPG, measuring heart rate, heart rate variability from video. The dataset contains facial videos and Blood Volume Pulse (BVP) data captured concurrently.
- Categories:
4615 Views
This dataset is a collection of images and their respective labels containing multiple Indian coins of different denominations and their variations. The dataset only contains images of one side of each coin (Tail side) which contains the denomination value.
The samples were collected with the help of a mobile phone while the coins were placed on top of a white sheet of A4-sized paper.
- Categories:
3658 Views
This dataset is a supplement of the paper DANCE: Domain Adaptation of Networks for Camera Pose Estimation: Learning Camera Pose Estimation Without Pose Labels [1]. The dataset contains a sample scene of a robot garage. The scene was captured by a Leica BLK360 laser scanner, and 16 scans were merged into a single point cloud of 118M colored points. The dataset also contains ~100k synthetically rendered images and scene coordinates generated form the point cloud.
- Categories:
231 Views
Opportunity++ is a precisely annotated dataset designed to support AI and machine learning research focused on the multimodal perception and learning of human activities (e.g. short actions, gestures, modes of locomotion, higher-level behavior).
- Categories:
2032 Views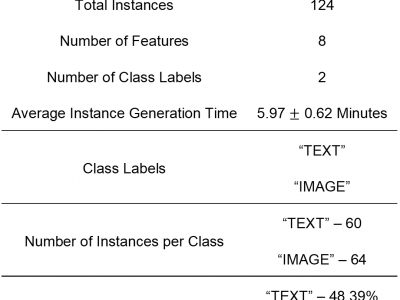
Human intention is an internal, mental characterization for acquiring desired information. From
interactive interfaces, containing either textual or graphical information, intention to perceive desired
information is subjective and strongly connected with eye gaze. In this work, we determine such intention by
analyzing real-time eye gaze data with a low-cost regular webcam. We extracted unique features (e.g.,
Fixation Count, Eye Movement Ratio) from the eye gaze data of 31 participants to generate the dataset
- Categories:
642 Views
Our datasets_PAGML isbased on two public benchmark datasets SHREC2013 and SHREC2014. Sketches are the same as the original datasets. Each 3D shape in the the original datasets is represented as 12 views.
- Categories:
177 Views
This dataset is composed by both real and sythetic images of power transmission lines, which can be fed to deep neural networks training and applied to line's inspection task. The images are divided into three distinct classes, representing power lines with different geometric properties. The real world acquired images were labeled as "circuito_real" (real circuit), while the synthetic ones were identified as "circuito_simples" (simple circuit) or "circuito_duplo" (double circuit). There are 348 total images for each class, 232 inteded for training and 116 aimed for validation/testing.
- Categories:
3615 Views