Datasets
Standard Dataset
Dataset of dual-pol Sentinel-1 SAR imagery for training despeckling filters
- Citation Author(s):
-
Ruben DarioVasquez-Salazar
 Faculty of Engineering, Politécnico Colombiano Jaime Isaza Cadavid, 48th Av, 7-15, Medellín, ColombiaAhmed AlejandroCardona-MesaFaculty of Sciences and Humanities, Institución Universitaria Digital de Antioquia, 55th Av, 42-90, Medellín 050010, Colombia. Faculty of Engineering, Politécnico Colombiano Jaime Isaza Cadavid, 48th Av, 7-151, Medellín 050022, ColombiaJean PierreDíaz-PazFaculty of Engineering, Politécnico Colombiano Jaime Isaza Cadavid, 48th Av, 7-15, Medellín, ColombiaCarlos ManuelTravieso-GonzálezInstitute for Technological Development and Innovation in Communications (IDeTIC), Universidad de Las Palmas de Gran Canaria, SpainLuisGómezElectronic Engineering and Automatic Control Department, IUCES, Universidad de Las Palmas de Gran Canaria, Spain
Faculty of Engineering, Politécnico Colombiano Jaime Isaza Cadavid, 48th Av, 7-15, Medellín, ColombiaAhmed AlejandroCardona-MesaFaculty of Sciences and Humanities, Institución Universitaria Digital de Antioquia, 55th Av, 42-90, Medellín 050010, Colombia. Faculty of Engineering, Politécnico Colombiano Jaime Isaza Cadavid, 48th Av, 7-151, Medellín 050022, ColombiaJean PierreDíaz-PazFaculty of Engineering, Politécnico Colombiano Jaime Isaza Cadavid, 48th Av, 7-15, Medellín, ColombiaCarlos ManuelTravieso-GonzálezInstitute for Technological Development and Innovation in Communications (IDeTIC), Universidad de Las Palmas de Gran Canaria, SpainLuisGómezElectronic Engineering and Automatic Control Department, IUCES, Universidad de Las Palmas de Gran Canaria, Spain - Submitted by:
- Ruben Vasquez-S...
- Last updated:
- Fri, 10/18/2024 - 08:22
- DOI:
- 10.21227/6yfn-2z15
- Data Format:
- License:
 761 Views
761 Views- Categories:
- Keywords:
Abstract
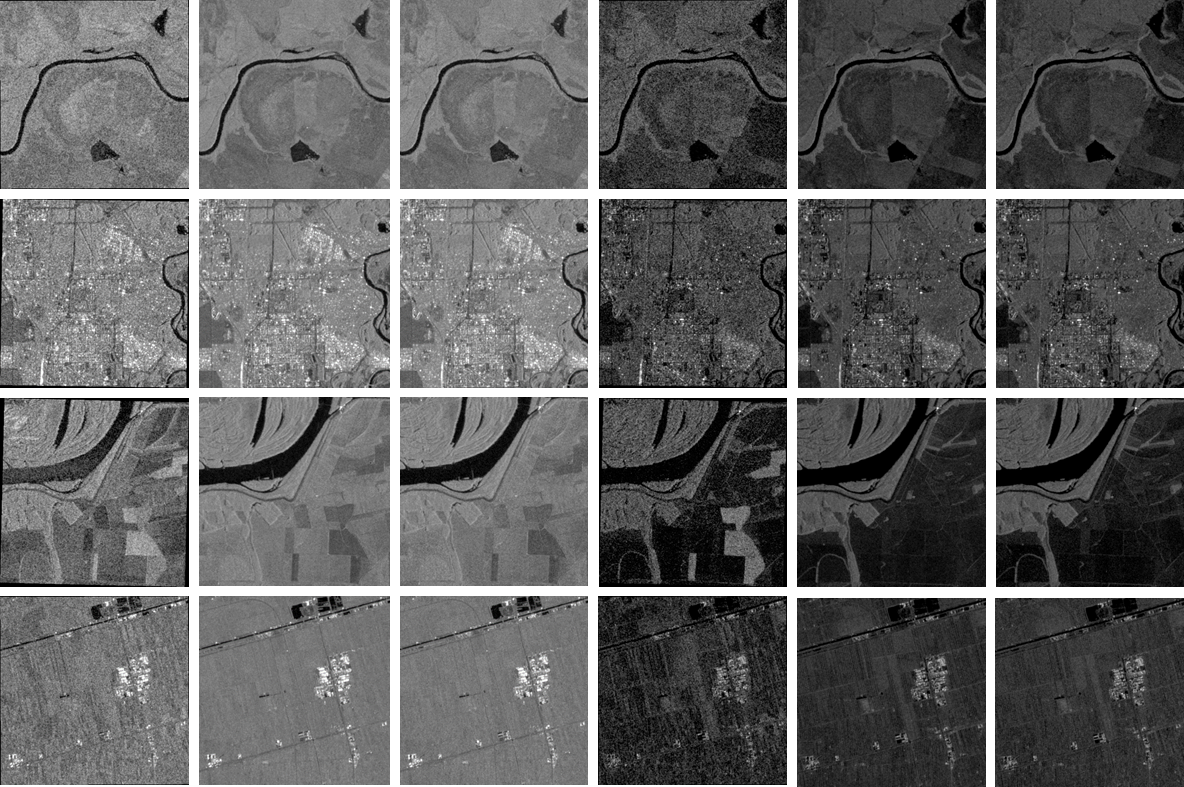
When training supervised deep learning models for despeckling SAR images, it is necessary to have a labeled dataset with pairs of images to be able to assess the quality of the filtering process. These pairs of images must be noisy and ground truth. The noisy images contain the speckle generated during the backscatter of the microwave signal, while the ground truth is generated through multitemporal fusion operations. In this paper, two operations are performed: mean and median. The mean operations have been previously used, which integrate several registered images of the same region by an average operation. The proposed median operation improves the speckle reduction since it ignores the extreme values of the pixels. The Sentinel-1 GRD images belong to random locations and dates, which makes the dataset more heterogeneous. From this, the trained models will improve their generalization. The designed dataset is composed of 12,600 images, including both VV and VH polarizations and their corresponding generated ground truth. This dataset is available for scientists who train machine or deep learning despeckling models and have a ground truth reference to assess the quality of their results.
The images in the dataset are organized in six folders, namely:
'SAR VH' and 'SAR VV' which contain actual SAR images in VH and VV polarizations corresponding to the first image of each collection, respectively
'GT MEAN VH' and 'GT MEAN VV' which contain the generated ground truth by averaging the VH and VV polarizations, respectively
'GT MEDIAN VH' and 'GT MEDIAN VV' which contain the generated ground truth by calculating the median of the VH and VV polarizations, respectively
Dataset Files
- GT MEAN VH.zip (561.97 MB)
- GT MEAN VV.zip (559.24 MB)
- GT MEDIAN VH.zip (576.23 MB)
- GT MEDIAN VV.zip (578.27 MB)
- SAR VH.zip (428.21 MB)
- SAR VV.zip (440.05 MB)






Comments
.