*.tif

This dataset includes three types: DEM, land cover data, and high-definition remote sensing images.
Among them, the DEM data has an accuracy of 30 meters and is used to calculate the slope value. The land cover data has an accuracy of 8.98 meters and is located in a field area in southern Taiwan, China, and is used to extract coarse-grained land object types. The high-definition remote sensing data is taken by drones with an accuracy of 0.03 meters and is used for unsupervised classification of land objects.
- Categories:
 181 Views
181 Views
Greenland Ice Sheet is one of the key factors influencing global climate change. Its slight variations can lead to significant changes in sea level, making quantitative research on its mass balance of great scientific importance.
- Categories:
4 Views
Facility agriculture and arable land data play crucial roles in modern agricultural management and sustainable development. Accurate and up-to-date information regarding facility agriculture, including greenhouses, hydroponic systems, and other controlled environments, enables farmers and policymakers to make informed decisions. It helps in optimizing resource use, improving crop yields, and ensuring food security. Meanwhile, arable land data are essential for monitoring and managing the availability and quality of land suitable for cultivation.
- Categories:
95 Views
Abstract
- Categories:
307 Views
The detection of the collapse of landslides trigerred by intense natural hazards, such as earthquakes and rainfall, allows rapid response to hazards which turned into disasters. The use of remote sensing imagery is mostly considered to cover wide areas and assess even more rapidly the threats. Yet, since optical images are sensitive to cloud coverage, their use is limited in case of emergency response. The proposed dataset is thus multimodal and targets the early detection of landslides following the disastrous earthquake which occurred in Haiti in 2021.
- Categories:
1074 Views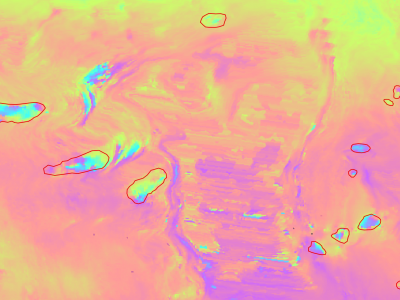
Slow moving motions are mostly tackled by using the phase information of Synthetic Aperture Radar (SAR) images through Interferometric SAR (InSAR) approaches based on machine and deep learning. Nevertheless, to the best of our knowledge, there is no dataset adapted to machine learning approaches and targeting slow ground motion detections. With this dataset, we propose a new InSAR dataset for Slow SLIding areas DEtections (ISSLIDE) with machine learning. The dataset is composed of standardly processed interferograms and manual annotations created following geomorphologist strategies.
- Categories:
1305 Views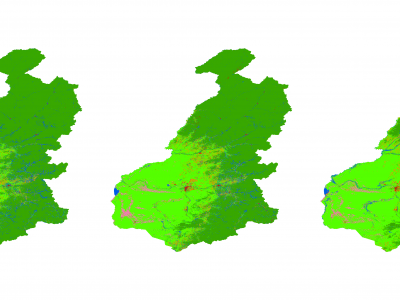
Generating accurate thematic land use maps is importance in ecologically vulnerable regions, especially considering the challenges associated with extracting the forest-steppe ecotone and its associated uncertainties and high error rates. By employing the Principal Component Analysis (PCA) method to integrate Sentinel-1 and Sentinel-2 imagery, high-resolution (10 meters) land use cover products were generated for the forest-steppe ecotone of the Greater Khingan Mountains from 2019 to 2021.
- Categories:
159 Views
Synthetic Aperture Radar (SAR) satellite images are used increasingly more for Earth observation. While SAR images are useable in most conditions, they occasionally experience image degradation due to interfering signals from external radars, called Radio Frequency Interference (RFI). RFI affected images are often discarded in further analysis or pre-processed to remove the RFI.
- Categories:
348 Views
The optical remote sensing (ORS) ship dataset contains eight ship classes (i.e., bulk carrier, car carrier, cargo, chemical tanker, container, dredge, oil tanker, tug) with a total of 8678 pictures. All pictures are collected using Google Earth with sub-meter resolution and corresponding class information are matched with the official website[http://www.marinetraffic.com/]
- Categories:
497 Views
The presented dataset is a supplementary material to the paper [1] and it represents the X-Ray Energy Dispersive (EDS)/ Scanning Electron Microscopy (SEM) images of a shungite-mineral particle. Pansharpening is a procedure for enhancing the spatial resolution of a multispectral image, here the EDS individual bands, with a high-spatial panchromatic image, here the SEM image. Pansharpening techniques are usually tested with remote sensed data, but the procedures have been efficient in close-range MS-PAN pairs as well [3].
- Categories:
591 Views