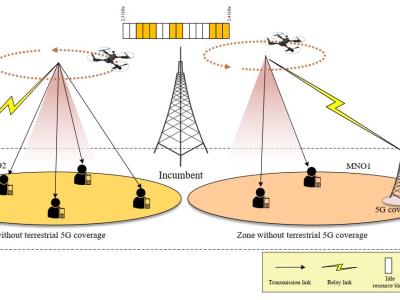
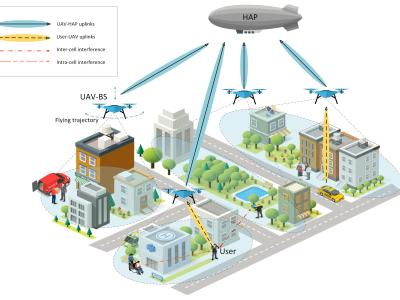
This dataset accompanies the study “Universal Metrics to Characterize the Performance of Imaging 3D Measurement Systems with a Focus on Static Indoor Scenes” and provides all measurement data, processing scripts, and evaluation code necessary to reproduce the results. It includes raw and processed point cloud data from six state-of-the-art 3D measurement systems, captured under standardized conditions. Additionally, the dataset contains high-speed sensor measurements of the cameras’ active illumination, offering insights into their optical emission characteristics.
- Categories: