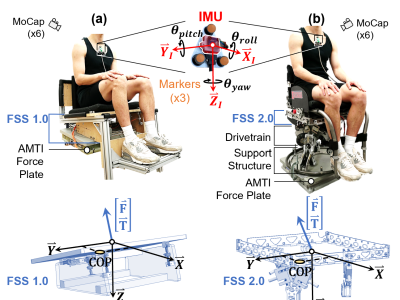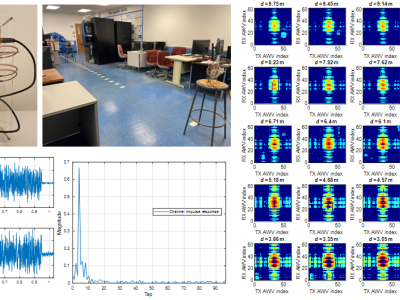
The large number and scale of natural and man-made disasters have led to an urgent demand for technologies that enhance the safety and efficiency of search and rescue teams. Semi-autonomous rescue robots are beneficial, especially when searching inaccessible terrains, or dangerous environments, such as collapsed infrastructures. For search and rescue missions in degraded visual conditions or non-line of sight scenarios, radar-based approaches may contribute to acquire valuable, and otherwise unavailable information.
- Categories: